오늘은 딥러닝 끝내고 LLM을 들어가려고 했는데 sagemaker 거의 4시간 했는데 너무 오류도 많고 효율적이지도 않고 학생들 모두 진행이 안되서 일단 보류하고
sagemaker는 결론적으로 모든것을 aws상에서 구동하기보다는 로컬과 s3를 적절히 섞어서 진행하는것이 맞다는 내용이었다.
그래서 sagemaker는 기초세팅정도만 정리하겠다.
이 후 bedrock을 통해서 llm을 불러와서 모델을 사용하는 실습을 진행했다.
Sagemaker AI 기본 구성 & NO-CODE GUI 기반 딥러닝 실습
- 정의
- 포괄적인 AI및 분석 서비스를 통합환경을 제공하는 서비스
- 데이터 처리, SQL 분석, 모델 개발, 모델 학습, 모델 서빙(엔드포인트 구성),생성형AI
- 고가 비용 문제점임
- 포괄적인 AI및 분석 서비스를 통합환경을 제공하는 서비스
- 구성
- 도메인 - 작업에 대한 공간(건물)

- Studio - 공간 내에서 작업을 할 수 있는 IDE(회사)
- Canvas - 회사 내의 업무/상세작업 (데이터 수집 → 전처리 → 모델 학습 → 엔드포인트 구성)
- 모델 파이프라인 구축
- no-code 기반(코딩 없이 구성 가능함 - ui 제공)
- Jupyter notebook/lab
- 코드 기반으로 구성
- …
- Canvas - 회사 내의 업무/상세작업 (데이터 수집 → 전처리 → 모델 학습 → 엔드포인트 구성)
- 도메인 구성
- Environment configuration > 도메인 > 도메인 생성
- 단일 사용자용 설정 (기본값 유지) > 설정
- 생성중 화면
- 도메인 세부 정보 (도메인 생성 완료 후 자동 포워딩)
- 도메인 삭제
- 세부정보에서 하위 이동 > 현재는 비활성(다른 리소스가 잡고있다)
- 사용자 프로필 메뉴에 자동으로 생성된 프로필 존재
- 앱 구성 > 하위 이동
- canvas 해당부분 편집
- 편집 버튼 클릭
- ML 운영 구성 모두 활성화
- 로컬 파일 업로드 활성화
- 앱 구성 > canvas 확인
- studio 구성

- 대쉬보드 > 도메인 클릭(서비스 상태 확인됨) > studio 열기 클릭
- STUDIO APPLICATION 목록
- MLflow : MLOps 용도
- JupyterLab : 파이썬/R 기반 노트북, 분석, 학습 용도
- RStudio : R기반
- Canvas : no-code 기반
- code editor : 프로그래밍 에디터
- canvas 클릭
- 비전공자를 위한 앱, GUI기반 ML 처리
- 데이터 준비, 공급 → 모델 훈련 → 예측 → 전체를 파이프라인으로 FLOW 구성
- no-code ML, 생성형 AI
- 비전공자를 위한 앱, GUI기반 ML 처리
- canvas 클릭
- STUDIO APPLICATION 목록

- 특징
- Build and use ML and generative AI models - no code required
- Data Wrangler 메뉴 진행

- import and prepare > Tabular 선택
- 집값 데이터 선택
- select a data source > Canvas Datasets
- 참고 : S3, 로컬파일,스노우 플레이크, RDB 다양한 자원에서 가져올 수 있음
- 데이터 파이프라인과 모델 파이프라인이 만나는 지점(연결지점)
- 현재는 모델 파이프라인만 확인중 > 제공되는 데이터 사용 > 기본값
- XXXX_housing_xxx 집값 데이터 사용
- select a data source > Canvas Datasets
- 집값 데이터 선택

- 데이터 구성
- 데이터 표본 제공
- 샘플링 방식 - random 기본값이니 random ㄱㄱ (기본 추천값, 회귀 문제) 1000개
- 노드 기반으로 파이프라인 구성
- 데이터 스케일, 분포등 EDA 가능
- 피처 엔지니어링 가능(부분적) → 데이터 전처리 가능
- 데이터 스케일, 분포등 EDA 가능
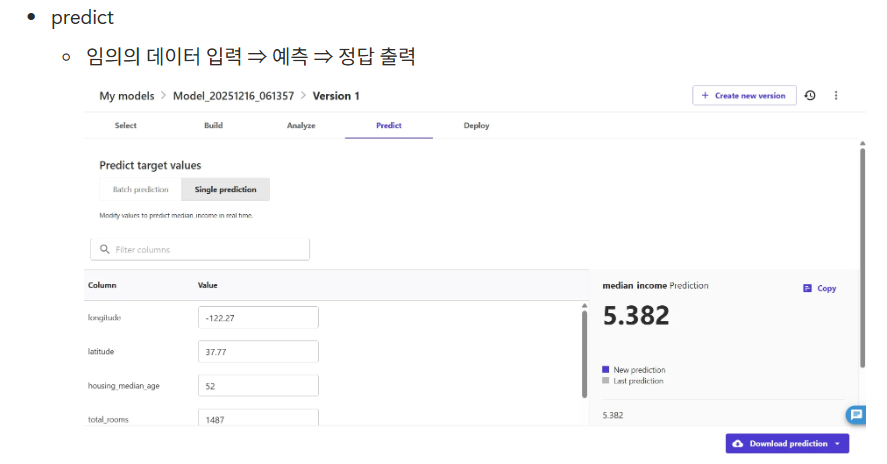
예측분석(모델타입)과 타겟 컬럼(정답) 지정

- export and create model
- 모델 빌드 메뉴
- 정답 분포, 모델 예측 데이터에 대한 소개, 데이터 샘플 등 표기
- quick build 클릭 → 이게 모델 학습(AutoML 적용)
- 모델 빌드 완료 후
- my model에서 확인 가능
- 정답 분포, 모델 예측 데이터에 대한 소개, 데이터 샘플 등 표기

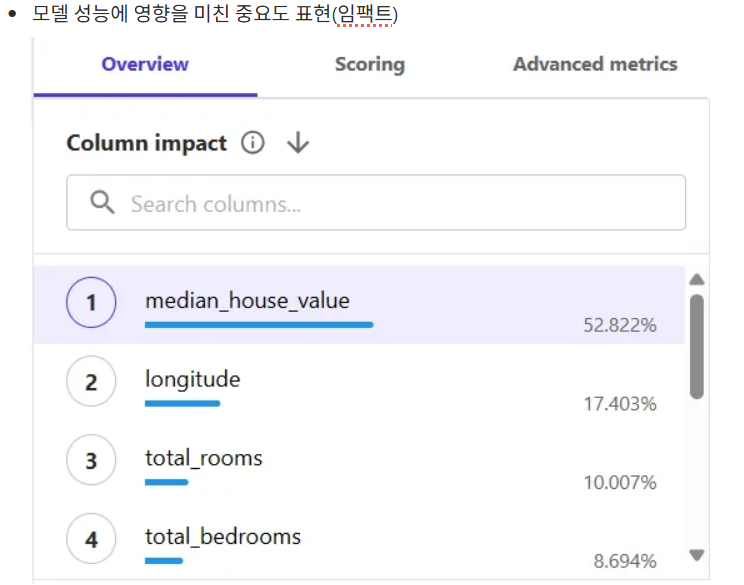
- 모델 상세 내용

- 해당 모델은 회귀 (연속형 수치데이터 예측하는 모델)
- 손실값 ⇒ 0.933(rmse), mse(0.871) Canvas


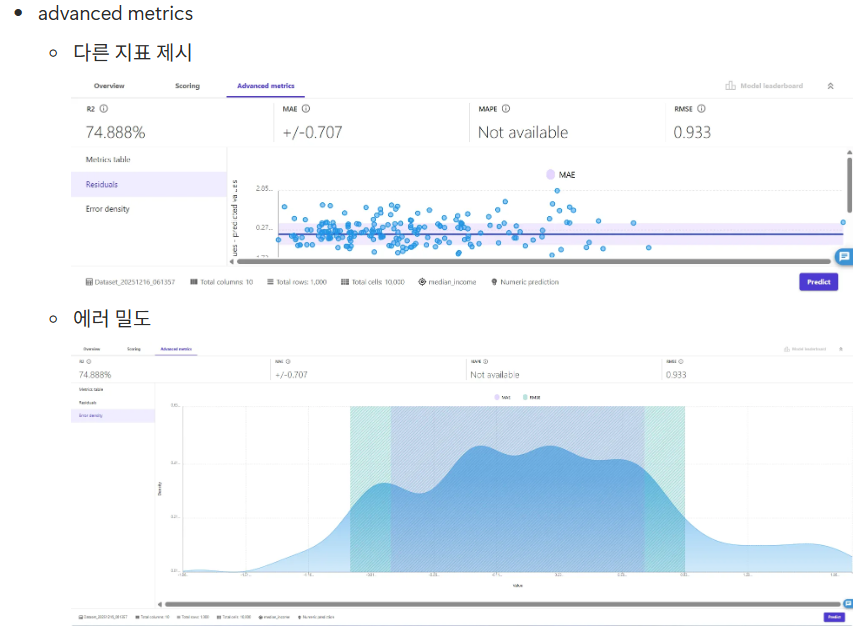
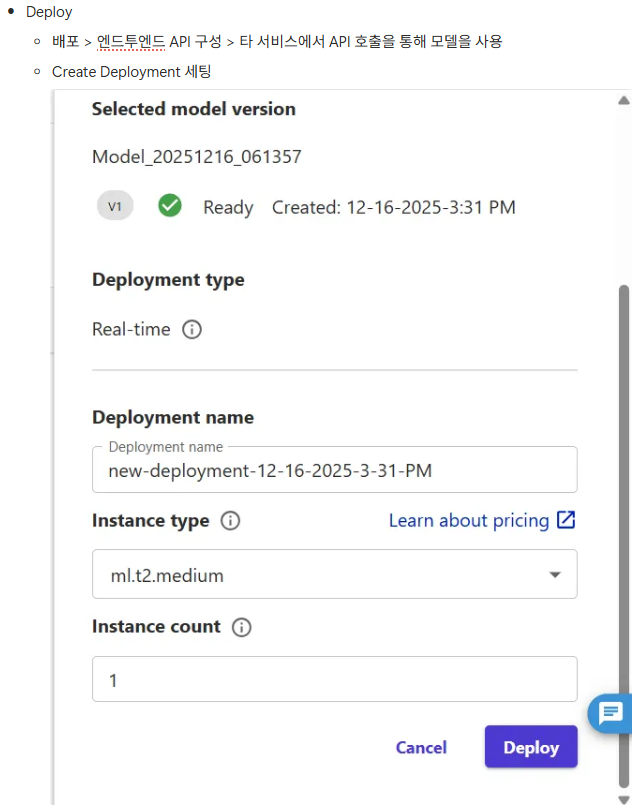
- deploy 클릭 > 잠시후 > 엔드포인트 구성 완료 (api 사용 가능해짐)
- 해당 모델은 v1 버전
- view detail 클릭

- 상세 정보
- 엔드포인트 관련 배포 이름
- canvas-new-deployment-12-16-2025-3-31-PM
- 샘플 코드 확인
- 엔드포인트 관련 배포 이름

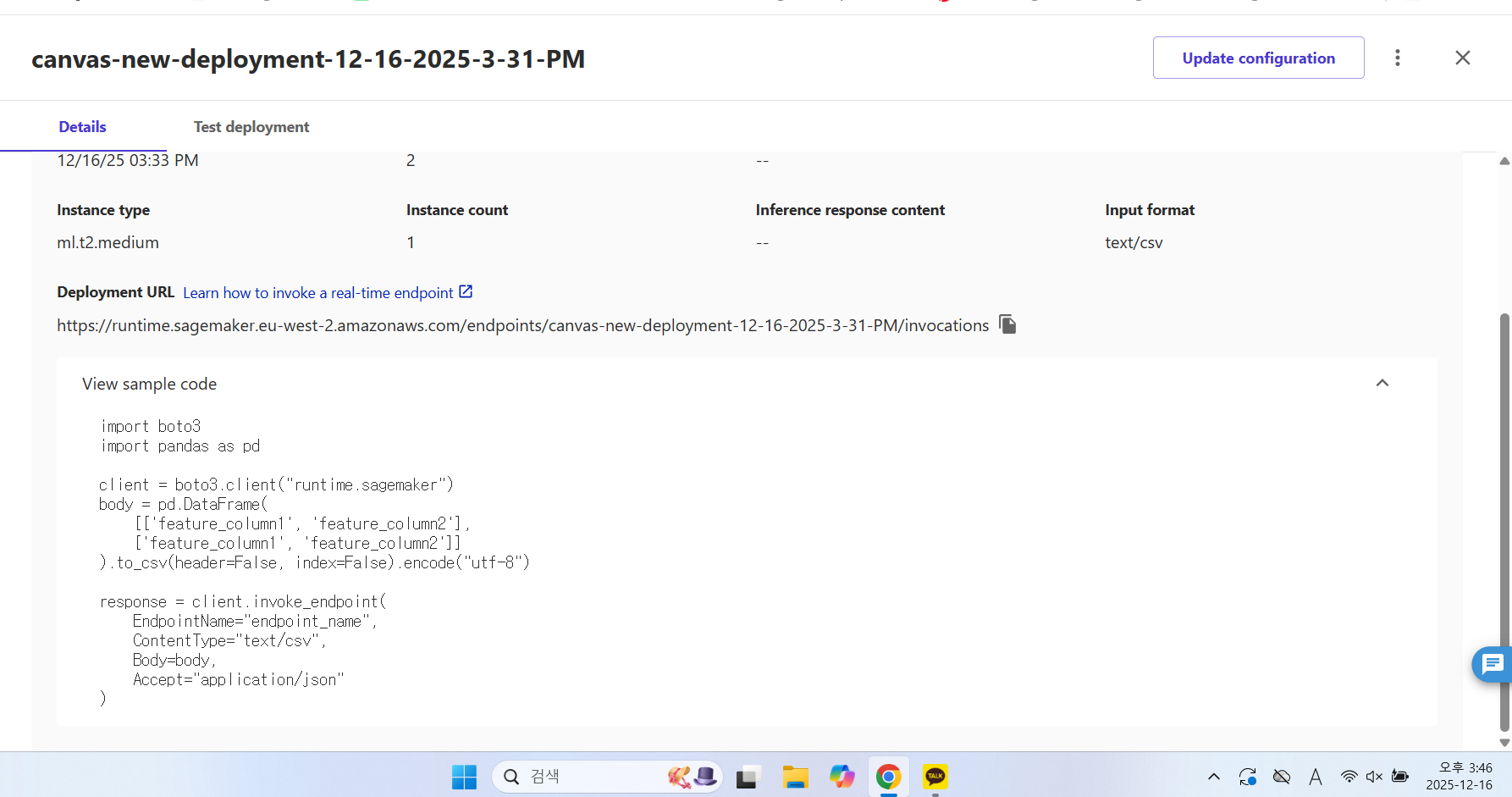
이렇게 코드 한 줄 치지않고 딥러닝과 시각화까지 할 수 있었다.
비전공자들을 위한 딥러닝 프로그램이라고 한다.
물론 편하게 딥러닝을 수행할 수 있다는 점에서는 큰 장점이 있지만 코드를 만지고 디테일을 수정하며 더 좋은 결과를 내야 하기에 결국 코드 기반으로 딥러닝을 수행할 수 있는 능력이필요하다.
이제 LLM Bedrock으로 넘어간다.
AWS Bedrock
FM(기본 모델)을 사용하여 생성 AI 애플리케이션을 구축하고 확장
- 튜토리얼 사용
- 과거 ⇒ LLM모델 엑세스 신청 ⇒ 허가 ⇒ 사용
- 현재 ⇒ 바로 사용, 필요시 동의 절차
- LLM 사용에 대한 flow 구성(코드 레벨로 LLM 호출하여 프롬프트 처리 진행)
- 본 목적을 위해서 Bedrock에 공급하는 업체 중 Anthropic 사의 모델 Claude 3 Sonnet을 사용한다.
- (다른 사람들은 3.5 나만 리전 없어서 3.0)
- 모델 ID : anthropic.claude-3-sonnet-20240229-v1:0
- 해당 ID를 통해서 해당 LLM 모델을 사용
- 이미지를 텍스트 및 코드로 변환
- 다국어 대화
- 복잡한 추론 및 분석
- 한국어 뉘앙스 탁월하게 표현
- 해당 ID를 통해서 해당 LLM 모델을 사용
- 코드 작성
- AWS 내부
- AWS 외부
- AWS access key 사용
- Amazon Bedrock API 키
- 키 발급
- 단기 API 키 발급
- 모델 ID : anthropic.claude-3-sonnet-20240229-v1:0
이후 코랩에서 진행
개요
- AWS Bedrock에서 제공하는 LLM 모델 사용
- AWS 외부에서 접근하므로 엑세스 키가 필요함
- Bedrock 단기 access key 사용



!pip install boto3
import boto3
import json
import os # 환경변수로 AWS_BEARER_TOKEN_BEDROCK 값이 설정되어있어야함 -> 자동 인식
from dotenv import load_dotenv # .env 파일을 읽어서 os 단 환경변수로 세팅해주는 함수mport boto3
import json
import os # 환경변수로 AWS_BEARER_TOKEN_BEDROCK 값이 설정되어있어야함 -> 자동 인식
from dotenv import load_dotenv
def prompt_llm_invoke(prompt_msg):
if not api_key:
return'bedrock 키가 존재하지 않습니다.'
# 1. Bedrock 클라이언트 획득
try:
bedrock = boto3.client(service_name='bedrock-runtime',
region_name = REGION)
# 2. 프롬프트 구성 -> 모델별, 버전별 상이할 수 있음
# 모델이 변경되면, 프롬프트도 수정 -> 범용성 프롬프트 -> 랭체인(고수준 API(프롬프트 템플릿)를 제공하여 공통 형식 제공)
# 'anthropic.claude-3-sonnet-20240229-v1:0/3 버전 호환 프럼프트임
prompt = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": prompt_msg
}
]
}
# 3. 모델 호출 -> 프럼프트 전달
res = bedrock.invoke_model(
modelId = llm_id,
body = json.dumps(prompt)# 딕셔너리 => 객체직렬화 => 문자열(jsom 형태)
)
# 4. 결과 출력
body = json.loads(res['body'].read()) # 객체 역직렬화 (문자열 -> 딕셔너리)
# print(body)['content'][0]['text']
return body['content'][0]['text']
except Exception as e:
print('오류',e)
results = prompt_llm_invoke('''
프롬프트 엔지니어링에 대한 간단한 개념정리해줘
''')
print(results)
----------------------------
프롬프트 엔지니어링(Prompt Engineering)은 대화형 AI 시스템이나 대규모 언어모델에 올바른 프롬프트(Prompt)를 제공하여 원하는 결과를 얻는 기술을 말합니다. 여기서 프롬프트란 AI 모델에 입력으로 제공되는 문장이나 지시사항을 의미합니다.
주요 개념은 다음과 같습니다:
1. 프롬프트 구성: 모델에 입력할 프롬프트의 형식, 길이, 문맥 정보 등을 결정합니다. 잘 설계된 프롬프트는 모델의 성능을 크게 향상시킬 수 있습니다.
2. 프롬프트 주입(Prompt Injection): 주요 태스크에 관련된 지식이나 제약조건을 프롬프트에 포함시켜 모델의 출력을 원하는 방향으로 유도합니다.
3. 프롬프트 프로그래밍: 특정 작업을 수행하기 위해 프롬프트를 프로그래밍하는 방법으로, 조건문, 반복문 등을 통해 복잡한 태스크를 수행할 수 있습니다.
4. 프롬프트 튜닝: 프롬프트를 미세 조정하여 모델의 성능을 개선합니다. 프롬프트의 길이, 토큰 선택 등을 변경하며 최적의 프롬프트를 찾습니다.
5. 프롬프트 마이닝: 대량의 데이터에서 유용한 프롬프트를 자동으로 추출하는 기술입니다.
프롬프트 엔지니어링은 대규모 언어모델의 성능을 극대화하고 실제 애플리케이션에 적용할 수 있도록 돕는 중요한 기술입니다.LLM 모델을 가져와서 코랩에서 돌렸다!

GRADIO를 통해서 챗봇을 만들어서 GPT따라하기도 진행하였다.
오늘의 수업은 여기까지
AWS가 잘 안되서 속상하다 진짜 빡세게 했는데
계속 안돼서 오랜만에 머리가 터져버릴뻔했다.
나만 다른 부분에서 안되고 CLOUDSHELL로 들어가도 나는 복사도 안돼고 아우 너무 힘들었다.
그래도 다들 안되고 너무 느려서 나 혼자만 안되는게 아니라서 다행?인 하루였다
'ASAC-SK플래닛 T아카데미 데이터 엔지니어' 카테고리의 다른 글
| 25.12.19 52일차 [LLM | langchain, PromptTemplate, FewShot, Bedrock 연동, llm_langchain_bedrock 기반 서비스 만들기 실습] (0) | 2025.12.19 |
|---|---|
| 25.12.18 51일차 [LLM | Bedrock, 프롬프트 엔지니어링, 모델별 특화 예시] (1) | 2025.12.18 |
| 25.12.16 49일차 [딥러닝_전이학습 | 딥러닝_NLP_트랜스포머기반_전이학습_GPT2기반_제로샷러닝_리뷰감정분석] (1) | 2025.12.16 |
| 25.12.15 48일차 [딥러닝_NLP_워크플로우_챗봇구성, 활성화 함수] (0) | 2025.12.15 |
| 25.12.12 47일차 [딥러닝 | 개요, NLP 모델] (0) | 2025.12.15 |