오늘은 airflow에서 elasticsearch 의 개념과 opensearch의 개요, 수업과
opensearch를 이용한 대시보드 구성 방법을 실습하고
이후 kafka의 이론과 첫 기초단계 실습을 진행하였다.
Elasticsearch, AWS OpenSearch 이해
- Elasticsearch
- Apache Lucene에 구축되어 배포된 검색(원하는 정보를 검색해) 및 분석(데이터 분석) 엔진
- 방대한 양의 데이터를 신속하게(거의 실시간)저장, 검색, 분석을 수행할 수 있음
- 데이터 발생하는 곳 → 전달(지연이 있을 수 있음) → Elasticsearch
- 장점
- 고가용성 : 분산 구조(노드, Replica 샤드)를 통해 서비스 중단 없이 이용 가능
- 데이터를 여러곳에 분산 저장 → 그 한곳이 장애 발생해도 금방 복구, 카피, 서비스 지속됨
- Scale Out : 샤드를 통해 규모가 수평적으로 늘어날 수 있다. → 병렬, 분산
- Restful API : GET,PUT,POST,DELETE의 API를 제공하여 다양한 플랫폼에서 쉽게 접근 가능
- 검색어에 대한 인덱싱이 구축되어 있어서 빠르게 응답 가능
- 인덱싱 ⇒ 데이터를 쌓을 때 구분값 ⇒ 특정 로그(A공장 45구역 센서들)
- 검색어에 대한 인덱싱이 구축되어 있어서 빠르게 응답 가능
- Schema Free : Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없음
- json : 반정형 데이터 → 데이터와 구조를 같이 가진 데이터 형식(json, xml)
- 실시간 검색 : 거의 실시간 검색을 제공하는 것 처럼 빠른 처리
- 역색인 : 특정 단어를 찾을때 단어가 포함된 특정 문서의 위치를 알아내어 빠르게 결과를 찾아낼 수 있다.
- 고가용성 : 분산 구조(노드, Replica 샤드)를 통해 서비스 중단 없이 이용 가능
- 단점
- 완전한 실시간 X (Near real-time) : Elasticsearch는 데이터 저장 시점에 해당 데이터를 인덱싱함
- 트랜잭션과 롤백 기능이 없다. : 전체적인 클러스터의 성능 향상을 위해서 시스템적으로 비용 소모가 큰 롤백과 트랜잭션을 지원하지 않음
- 데이터 삭제 및 수정의 비효율성 : 실시간 검색과 분석을 위해 설계되었기 때문에 데이터 삭제나 수정 작업은 상대적으로 비효율적임.(Elasticsearch 에서의 업데이트는 기존 문서를 삭제하고 다시 삽입하는 방식)
- Amazon OpenSearch Service (구 Elasticsearch Service)
- ELK Stack을 AWS에서 가장 간편하게 구성하는 방법
- AWS가 설치, 패치, 백업을 다 해주기 때문에 서버를 직접 관리할 필요가 없음
- Apache 2.0의 라이센스였던 Elasticsearch가 7.10 버전 이후부터 SSPL 라이선스로 변경하자 모든 코드를 오픈해야했음
- AWS에서 Elasticsearch 7.10 (완전 무료 오픈소스)를 기반으로 포크하여 만든 프로젝트
- 구조
- 클러스터 (Cluster)
- 정의: 전체 시스템의 가장 큰 테두리. 하나 이상의 노드(서버)가 모여서 구성된 전체 집합.
- 역할: 모든 데이터를 보유하고 통합된 색인 및 검색 기능을 제공.
- 노드 (Node)
- 정의: 클러스터를 구성하는 개별 서버(컴퓨터).
- 역할: 실제로 데이터를 저장하고, 검색 요청을 처리하는 파트.
- 인덱스 (Index)
- 정의: 비슷한 특성을 가진 데이터들의 논리적인 집합. (RDBMS의 Database와 유사한 개념)
- 역할: 사용자는 이 '인덱스'를 대상으로 검색을 요청. 하지만 실제 데이터는 쪼개져서 노드에 저장됨
- 샤드 (Shard)
- 정의: 거대한 **인덱스를 물리적으로 나누어 놓은 조각(파티션)**입니다.
- 역할: 데이터를 여러 노드에 분산시켜 저장함으로써 대용량 처리를 가능하게 하고 성능을 높임. (그림에서 하나의 인덱스가 샤드 1, 샤드 2로 나뉘어 각각 다른 노드에 저장된 것을 볼 수 있음.)
- 종류
- 복제본을 통해 데이터의 안정성과 가용성을 보장
- Primary shard
- 모든 Document(데이터)들은 하나의 primary shard에 저장된다. Primary shard의 기본 개수는 5개이다. 처음 인덱스 생성 시점에서 설정 이후 변경 불가능
- Replica shard
- Primary shard의 복제본이다. 원본 데이터에 fault 발생시 복구하기 위해 사용된다 (fault tolerance). Replica shard의 기본 개수는 1개이다.
- 클러스터 (Cluster)

- 각 노드에 프라머리 샤드와 레플리카 샤드가 분산되어서 있어, 어떤 노드가 장애가 발생해도 복제하여 복구 가능하다.
- 도큐먼트 (Document)
- 정의: 저장되는 데이터의 **최소 단위**. (보통 JSON 형식)
- 위치: 실제로는 특정 샤드 내부에 저장되어 있음.
어제 게시글에 있는 로그 제너레이터 코드와 로그 리더 코드를 실행한다면 오픈서치에서 이를 시각화 할 수 있다.
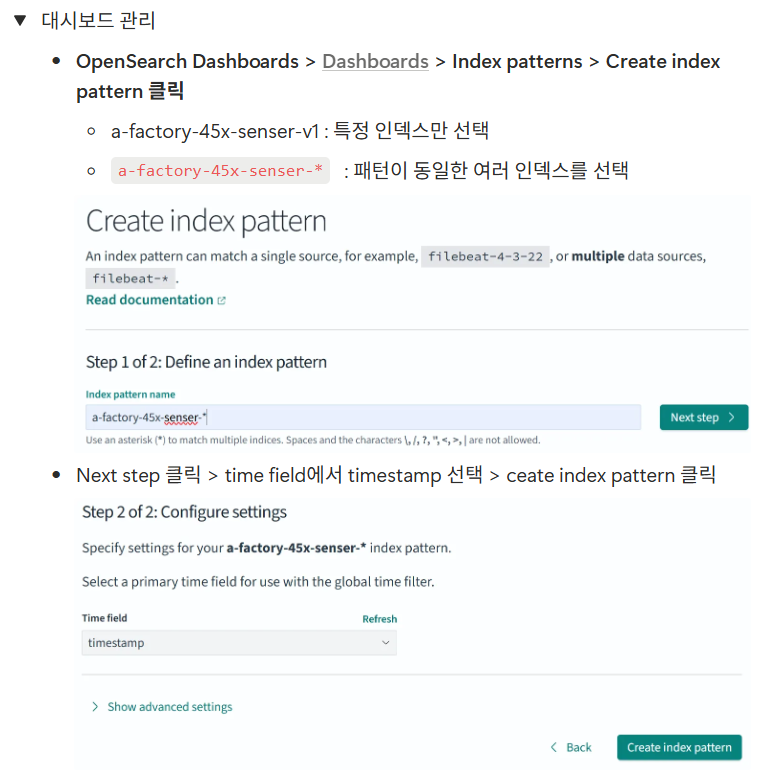
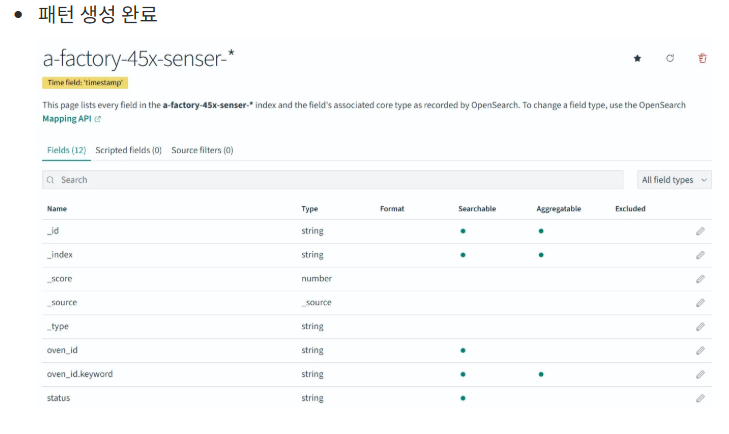

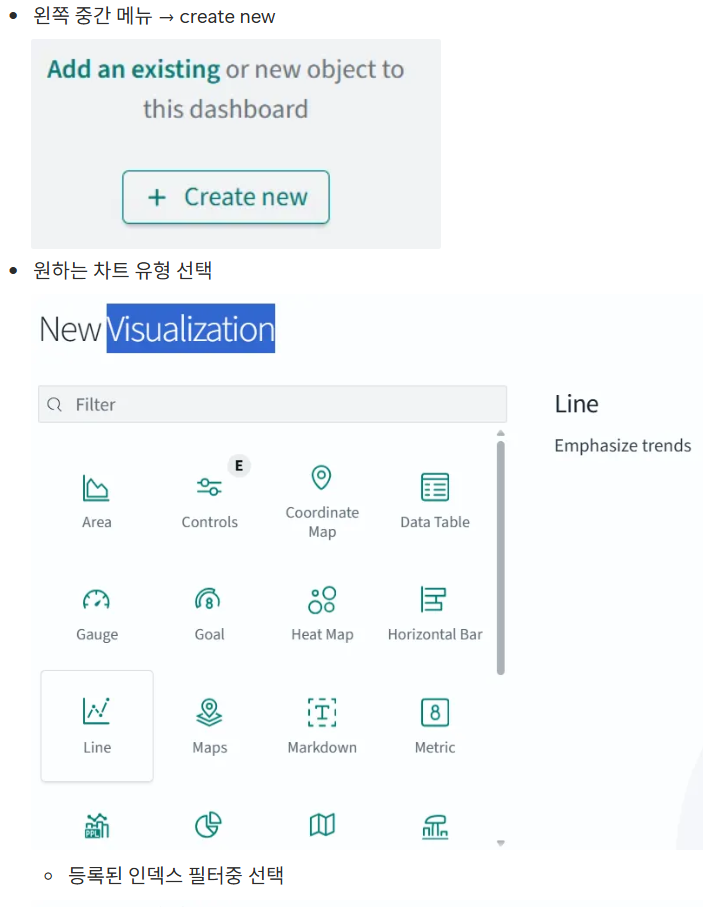


이렇게 opensearch상에서 인덱스를 시각화해서 처리할 수 있다.

추후 grafana를 사용하면 이런 식으로도 시각화가 가능하다, 제공하는 ui로도 충분히 멋지게 가독성 있게 가능하다.
kafka
- 실시간 스트리밍 데이터(대용량) 처리 - 카프카
- Kafka
- 개요
- 데이터를 흘려보내는 이벤트 파이프라인
- 프로듀서(이벤트 발송) → 컨슈머(이벤트 수신)
- 크게 2개 포지션은 서로 다른 위치에 구성 가능
- 서비스
- 고객 → 배민 → 장바구니 → 주문 → 결제 → 완료 : 주문에 대한 이벤트 발송
- 매장 → 이벤트가 수신 → 알람 울림(”배달의 민족 주문!!”) → 주문 확정 → 조리→ 포장 → 배달
- 배민 일일(24시간) 이용자건수 ⇒ 556만 명 ⇒ 메세지 발송
- 대충 1초당 이용자 건수(동수로 계산) ⇒ xxx건수 대량 발생 ⇒ 웹에서 대응한다?
- 비동기적이면서, 각각 역활에 충실하게 메세지를 송수신하는 시스템 필요
- 실시간 스트리밍
- 서비스
- 구성
- Producer
- 발송인, 데이터를 만들어서 보내는 주체
- 센서, 웹로그, … → 발생 → Producer 전송 → 실시간 수집 가능
- Consumer
- 수취인, 데이터를 가져가서 쓰는 주체
- 대량 ⇒ Spark, ELK, Airflow
- Event(Message)
- 데이터 자체 (json 형태가 주로 보임)
{ "temp" : 200, "time":"26-13-15", .. } - Topic
- 데이터를 분류하는 기준 → elk에서는 인덱스로 비유해도 적절함(유사성 고려)
- Broker
- 카프카 서버 한대, 데이터를 잠시 보관
- docker 기반으로 카프카 서버 구성
- Partition
- 하나의 토픽을 병렬 처리를 위해서 여러 개로 쪼개는 행위(단위)
- Offset
- 컨슈머가 메세지를 어디까지 읽었는지 해당 위치 번호
- Consumer Group
- 하나의 토픽을 여러 컨슈머가 분담하여 처리할대, 묶는 단위 그룹
- Producer
- 유사 제품
- 메세징 시스템 : RabbitMQ
- 클라우드 기반 스트리밍 서비스 : AWS Kinesis (고비용)
- 클라우드 기반 메세징, 스트리밍 서비스 : NATS
- 데이터 스트리밍 : Redis Sreams
- 시뮬레이션
- kafka는 Docker compose 구성 (별건 프로젝트 구성)
- Producer(센서)는 Oven-Topic 이라는 데이터를 초당 1000(?)개 발생
- Broker(카프카)는 해당 데이터를 수신하는대로 paritioin하여 순서대로 쌓는다
- Consumer(s3/ELK/Spark)에서 해당 플랫폼에 설정된 시간 단위(처리시간 레벨에서)로 데이터 가져옴 → airflow가 적용될 수 있음
- 설치
- docker compose 내용을 작성
- 서비스
- 주키퍼
- 분산 시스템에서 서버간 구성관리, 동기화, 관리 등등… 역활 수행
- 카프카의 메타 데이터 관리, 클러스터 상태 유지
- 카프카
- 브로커 역활, 대용량 분산 메세지 관리, ..
- docker-compose.yaml
version: '3.8' services: zookeeper: image: wurstmeister/zookeeper container_name: zookeeper ports: - "2181:2181" kafka: image: wurstmeister/kafka container_name: kafka ports: - "9092:9092" environment: # 브로커 내부에서 바인할 주소 ( 0.0.0.0:9092) KAFKA_LISTENERS: PLAINTEXT://:9092 # 클라이언트 (python 작성하는)에서 카프카에세 접속할 주소 # 127.0.0.1:9092 KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://127.0.0.1:9092 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 # 토픽 KAFKA_CREATE_TOPICS: "factory-sensors:1:1" depends_on: - zookeeper - 주키퍼
- 개요
- Kafka
이제 이론이 끝나고 kafka 실습을 진행했다.
readme.MD
먼저 DOCKER로 KAFKA를 올려준다.
이후 producer 와 consumer로 나누어서 kafka실습을 진행한다.
bakery_producer.py
'''
일반 고객이 특정 매장의 메뉴를 주문한다.
주문 발생 (로그) ->
- 스마트폰 앱에 탑재
'''
# 1. 모듈 가져오기
from kafka import KafkaProducer
import json
import time
import random
from datetime import datetime
import logging
# 2. kafka 연결
producer = KafkaProducer(
bootstrap_servers=['127.0.0.1:9092'], # docker 상에 존재하는 kafka 주소
value_serializer=lambda x: json.dumps(x).encode('utf-8') # dict를 문자열로 -> 직렬화 과정
)
menus = ["빅맥세트", "김밥세트", "돈까스세트", "식빵", "케이크"]
# 3. 전송
def send_msg():
'''
더미로 가상 주문 데이터 생성
'''
while True:
# 3-1. 가상 주문 생성
order = {
"order_time" : datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"store_cd" : "BK-2026-00001",
"menu" : random.choice(menus),
"count" : random.randint(1,10)
}
# 3-2. 토픽("bk-orders")을 구성하여 전송
producer.send("bk-orders", value=order)
# logging.info(f"주문:{order['menu']} 수량:{order['count']}")
print(f"주문:{order['menu']} 수량:{order['count']}")
# 3-3. 강제 전송 (버퍼 비움)
# producer.flush()
# 3-4. 잠시 대기 -> 주문 간격 랜덤하게 조정
interval = 1 + random.random()/10
# print(interval)
time.sleep(interval)
pass
if __name__ == '__main__':
send_msg()- 서비스
- 고객 → 배민 → 장바구니 → 주문 → 결제 → 완료 : 주문에 대한 이벤트 발송
- 매장 → 이벤트가 수신 → 알람 울림(”배달의 민족 주문!!”) → 주문 확정 → 조리→ 포장 → 배달
- 배민 일일(24시간) 이용자건수 ⇒ 556만 명 ⇒ 메세지 발송
- 대충 1초당 이용자 건수(동수로 계산) ⇒ xxx건수 대량 발생 ⇒ 웹에서 대응한다?
- 비동기적이면서, 각각 역활에 충실하게 메세지를 송수신하는 시스템 필요
- 실시간 스트리밍
우리가 실습해볼 것은 이 과정이다.
배민에서 고객이 주문하면, 그 주문에 대한 결제내용, 주문번호, 제품,수량 등등을 매장에서 수신해서 알람이 울리고, 주문 확정짓고 포장 배달하기까지의 그 과정에서 가게에 들어오고, 가게에서 감지하는 수많은 실시간 스트리밍이다.
kafka에서는 topic이라는 broker를 사용해서 데이터를 전달해준다.
코드자체는 별거 없다,
bakery_consumer.py
'''
언제 올지 모르는 주문을 대기 (시스템 x) 상태일때
고객이 주문을 진행 -> 메세지 발생 -> 카프카 -> 전송됨
메세지를 수신하면 주문 확정 후 조립/ 생산 시작됨
- 설치된 단말 기계(포스,프린터 )
- airflow상에서 구동 -> 1회 가동 무한루프 등등 방법은 다양함
- 혹은 데몬처럼 구동중일수도 있음
- 로그를 획득 -> 매장에 알림 (현재 작업) -> 모니터로 띄우고, 프린트 출력, 사운드 재생
데이터 파이프라인 관점 : 후속 작업 s3 저장 (raw데이터 저장), opensearch(가공 후 저장)
'''
# 1. 모듈 가져오기
from kafka import KafkaConsumer
import json # 역직렬화 하여 메세지를 복원해야함
import time
# 2. kafka 연결
consumer = KafkaConsumer(
'bk-orders', # 구독할 토픽 이름 설정
bootstrap_servers=['127.0.0.1:9092'], # 카프카 서버
auto_offset_reset='latest', # 가장 최신 메세지부터 읽기
enable_auto_commit=True, # 자동 커밋
group_id='factory_group', # 컨슈머 그룹 id 지정 -> 여러 컨슈머가 같이 수신
value_deserializer=lambda x: json.loads(x.decode('utf-8')) # 역직렬화
)
print('매장 주문 모니터 가동 -> 주문 대기중')
# 이 프로그램이 가동되면 -> 배민등 플랫폼에서 주문 가능한 상태가 된다 (여기서는 시그널/이벤트는 생략)
today_order_no = 1
# 3. 메세지 수신
def recv_msg():
global today_order_no
while True:
for msg in consumer:
data = msg.value
print(f"주문 수신 : 주문번호: {today_order_no} | {data['menu']} 수량: {data['count']}개 주문 접수되었습니다")
today_order_no += 1
time.sleep(3)
# 차후 발전사항 (데이터 엔지니어 관점) -> s3 : 로그 데이터 원본 형태로 저장
# 차후 발전사항 (데이터 엔지니어 관점) -> etl : 로그 데이터 가공 -> s3/opensearch
# kafka -> s3 or ELK or EFK 진입 파이프라인
# 차후 하루 단위로 결산 -> airflow -> athena or redshift -> 분석 업무 가동
# 차후 발전사항 (데이터 엔지니어 관점) -> etl -> s3 -> 모델 학습 -> 모델 업데이트(MLOPS)
# 로그 : 웹 클릭, 사이트 방문 : 이커머스, 센서데이터 : 스마트팩토리/iot 등등
# 4. 프로그램 가동
if __name__ == '__main__':
recv_msg()
자 이제 각 코드들을 실행하면 어떻게 보여지는지 영상으로 보여드리겠다.
터미널 3개중
가장 왼쪽은 실시간으로 쌓이는 로그, 모든 json의 내용이고
가운데는 더미데이터:고객이 보내는 주문 내용
오른쪽은 가게에서 모니터링하고, 받는 주문 내용이다.
이렇게 데이터가 실시간으로 들어오는것을 감지하는, 실시간 스트리밍 데이터 처리 서비스가 kafka의 본질이다.
오늘의 수업은 여기까지
'ASAC-SK플래닛 T아카데미 데이터 엔지니어' 카테고리의 다른 글
| 26.01.21 73일차 [kafka + EFK 실습(Fluent Bit) | EMR + Airflow (spark)] (0) | 2026.01.21 |
|---|---|
| 26.01.20 72일차 [kafka connect | logstash 사용 s3,opensearch 적재] (0) | 2026.01.20 |
| 26.01.16 70일차 [Airflow | ELK_log_generator, reader] (0) | 2026.01.18 |
| 26.01.15 69일차 [airflow | athena query, sensor, ctas etl] (0) | 2026.01.18 |
| 26.01.14 68일차 [airflow 특강 | 취업 특강] (0) | 2026.01.18 |