오늘은 kafka + EFK 를 Fluent Bit를 사용해서 s3와 opensearch로 적재시키는 과정과
EMR( Elastic MapReduce ) 를 AIRFLOW를 통해서 S3와 SPARK 조합으로 빅데이터를 처리하는 과정을 실습하였다.(ING)
- Kafka + EFK
- Logstash (자바기반, ELK 제품군)→ Fluent-Bit (C기반) 업그레이드 진행
- Logstash : 메모리 1G 최소, Fluent-Bit : 20~50MB 최소
- 속도 : Logstash < Fluent-Bit : 구성 방식에 따라 다를 수 있음
LOGSTASH-> FLUENT BIT로 변경
1. 먼저 docker-compose.yaml에 fluent bit를 추가해준다
fluent-bit:
image: fluent/fluent-bit:2.2
container_name: fluent-bit
volumes:
# 설정 파일 마운트 (구성파일 공유)
- ./fluent-bit/fluent-bit.conf:/fluent-bit/etc/fluent-bit.conf
- ./fluent-bit/parsers.conf:/fluent-bit/etc/parsers.conf
environment:
# AWS 환경변수 전달 (.env -> 읽어서 컴포즈에 반영 -> 컨테이너 구성 -> os 환경변수 세팅)
AWS_ACCESS_KEY_ID: ${AWS_ACCESS_KEY_ID}
AWS_SECRET_ACCESS_KEY: ${AWS_SECRET_ACCESS_KEY}
AWS_OPENSEARCH_HOST: ${AWS_OPENSEARCH_HOST}
AWS_OPENSEARCH_USER: ${AWS_OPENSEARCH_USER}
AWS_OPENSEARCH_PASS: ${AWS_OPENSEARCH_PASS}
AWS_S3_BUCKET: ${AWS_S3_BUCKET}
depends_on:
- kafka
2. 그 이후 fluent-bit.conf 파일에 내용을 추가해준다, 하나하나 뜯어본다
전체 코드
# -------------
# 기본 구성, 로그 레벨, 파서 파일 설정등
# 키값 첫글자 대문자, 단어가 이어지면 _(스네이크), 새로운 단어 첫글자 대문자
# 스네이크 + 카멜 표기법
# -------------
[SERVICE]
Flush 1
Log_Level info
Parsers_File parsers.conf
# -------------
# kafka Cusumer
# -------------
[INPUT]
Name kafka
# 카프카 서비스의 내부 접속 주소
Brokers kafka:29092
# 프로듀서가 공급하는 메세지 토픽
Topics web_logs
Group_Id fluent-bit-group
# 메세지 포멧
Format json
# 태그 (원본 데이터의 표식)
Tag raw.logs
# -------------
# 데이터 전처리 : 구조 변경, 필요시 특정 데이터 삭제 등등..
# -------------
# payload 데이터를 추출하여 payload의 같은 레벨로 배치 -> 평탄화
[FILTER]
Name nest
# raw.logs 태그가 붙어있는 데이터를 대상(매칭)
Match raw.logs
# lift -> 꺼낸다 (상위 레벨로 이동)
Operation lift
# 대상 키 값
Nested_under payload
# 클론 raw.logs 태그만 있는 데이터 대상으로
# 조건 : ip라는 키 값이 존재하는 데이터를 대상으로 -> processed.logs 태그를 추가하여 복제
[FILTER]
Name rewrite_tag
Match raw.logs
# ip라는 필드가 존재하고, 데이터가 어떤 것이든 존재한다면,
# processed.logs 태그를 추가하여 true : 복제
Rule ip .* processed.logs true
Emitter_Name re_emitted_logs
# 오픈서치 전용 태그 (복사본에 작업) 특정 데이터 파트 삭제 (전처리 간주)
# 사본 조작 -> 전처리, 오픈서치용 (가공된 데이터만 업로드), s3(원데이터 업로드)
[FILTER]
Name record_modifier
Match processed.logs
# 불필요한 필드 제거
Remove_key topic
Remove_key partition
Remove_key offset
Remove_key error
Remove_key key
# 원 데이터에서 있던 필드
Remove_key user_agent
# 없는 필드를 작성하면? 테스트 (데이터별로 특정 필드가 있을수도, 없을수도 있음)
Remove_key evt
# -------------
# S3 업로드(raw data)
# -------------
[OUTPUT]
Name s3
Match raw.logs
Bucket ${AWS_S3_BUCKET}
Region eu-west-2
# 버킷 하위로 저장 경로 포맷 -> 로그 여러건을 묶어서 보낸다 -> 형태는 json
S3_Key_Format /raws/%Y/%m/%d/$UUID.json
# 묶는 단위 -> 전송 단위 -> 버퍼 설정 (1mb 혹은 1분이 지나면)
Total_File_Size 1M
Upload_Timeout 1m
# json 저장
Json_Date_Key @timestamp
Json_Date_Format iso8601
# -------------
# opensearch 업로드(preprocessing data)
# -------------
[OUTPUT]
Name opensearch
Match processed.logs
Host ${AWS_OPENSEARCH_HOST}
Port 443
TLS on
HTTP_User ${AWS_OPENSEARCH_USER}
HTTP_Passwd ${AWS_OPENSEARCH_PASS}
# web_logs-rt-2026.01.21
Index web_logs-rt
# 인덱스명 포맷 적용
Logstash_Format On
Logstash_Prefix web_logs-rt
Logstash_DateFormat %Y.%m.%d
# 기타 옵션, 템플릿 관리 기능 On
Suppress_Type_Name On
# -------------
# 로깅 (개발시 데이터 형태 확인)
# -------------
[OUTPUT]
Name stdout
# 모든 메세지 출력
Match *
먼저 가장 기본적으로 입력, 출력만 작동할 시에는 로그가 이렇게 나온다.
# -------------
# 기본 구성, 로그 레벨, 파서 파일 설정등
# 키값 첫글자 대문자, 단어가 이어지면 _(스네이크), 새로운 단어 첫글자 대문자
# 스네이크 + 카멜 표기법
# -------------
[SERVICE]
Flush 1
Log_Level info
Parsers_File parsers.conf
# -------------
# kafka Cusumer
# -------------
[INPUT]
Name kafka
# 카프카 서비스의 내부 접속 주소
Brokers kafka:29092
# 프로듀서가 공급하는 메세지 토픽
Topics web_logs
Group_Id fluent-bit-group
# 메세지 포멧
Format json
# 태그 (원본 데이터의 표식)
Tag raw.logs
# -------------
# 로깅 (개발시 데이터 형태 확인)
# -------------
[OUTPUT]
Name stdout
# 모든 메세지 출력
Match *로그
```
# 원본 메세지
전송 :{'ip': '117.15.47.192', 'timestamp': '2026-01-21 10:06:57', 'method': 'HEAD', 'url': 'http://vaughn-sullivan.com/', 'status_code': 466, 'user_agent': 'Mozilla/5.0 (Android 2.0.1; Mobile; rv:41.0) Gecko/41.0 Firefox/41.0'}
# fluent-bit 수신 메세지
# 원본 메세지(데이터)는 payload라는 키의 값으로 배치가 됨
# 새로운 구조 : topic, partition, offset, error, key, payload = 원본데이터
[0] raw.logs: [[1768957549.076465506, {}], {"topic"=>"web_logs", "partition"=>0, "offset"=>70, "error"=>nil, "key"=>nil, "payload"=>{"ip"=>"15.2.94.215", "timestamp"=>"2026-01-21 10:05:48", "method"=>"DELETE", "url"=>"http://www.green.net/", "status_code"=>472, "user_agent"=>"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10_10_2 rv:6.0; dz-BT) AppleWebKit/531.3.1 (KHTML, like Gecko) Version/5.0 Safari/531.3.1"}}]
```아무런 전처리 없이 로그가 전송된다,
여기서 수신 메세지를 보면 payload 밑에 원본 데이터들이 있는것을 볼 수 있다.
3. 여기서 필터 기능으로payload 밑에 있는 데이터들을 올려준다.
# 데이터 전처리 : 구조 변경, 필요시 특정 데이터 삭제 등등..
# -------------
# payload 데이터를 추출하여 payload의 같은 레벨로 배치 -> 평탄화
[FILTER]
Name nest
# raw.logs 태그가 붙어있는 데이터를 대상(매칭)
Match raw.logs
# lift -> 꺼낸다 (상위 레벨로 이동)
Operation lift
# 대상 키 값로그
- payload 내부값이 상위 레벨로 이동, payload 키값 자체를 삭제됨
```
[0] raw.logs: [[1768958335.030501895, {}], {"topic"=>"web_logs", "partition"=>0, "offset"=>91, "error"=>nil, "key"=>nil, "ip"=>"55.78.243.108", "timestamp"=>"2026-01-21 10:18:54", "method"=>"HEAD", "url"=>"https://www.ross.biz/", "status_code"=>228, "user_agent"=>"Mozilla/5.0 (Windows CE; tt-RU; rv:1.9.0.20) Gecko/6014-05-21 00:41:28 Firefox/3.6.20"}]
```payload 밑의 내용들이 위로 올라왔다
4. 원본은 s3로, 사본은 opensearch로 보내주기 위해서 사본에 tag를 변경해준다.
# 클론 raw.logs 태그만 있는 데이터 대상으로
# 조건 : ip라는 키 값이 존재하는 데이터를 대상으로 -> processed.logs 태그를 추가하여 복제
[FILTER]
Name rewrite_tag
Match raw.logs
# ip라는 필드가 존재하고, 데이터가 어떤 것이든 존재한다면,
# processed.logs 태그를 추가하여 true : 복제
Rule ip .* processed.logs true
Emitter_Name re_emitted_logs로그
```
[0] raw.logs: [[1768958739.005388667, {}], {"topic"=>"web_logs", "partition"=>0, "offset"=>92, "error"=>nil, "key"=>nil, "ip"=>"4.6.221.27", "timestamp"=>"2026-01-21 10:25:38", "method"=>"PATCH", "url"=>"http://www.henry.com/", "status_code"=>476, "user_agent"=>"Mozilla/5.0 (Windows; U; Windows NT 6.1) AppleWebKit/531.3.7 (KHTML, like Gecko) Version/5.0.4 Safari/531.3.7"}]
[0] processed.logs: [[1768958739.005388667, {}], {"topic"=>"web_logs", "partition"=>0, "offset"=>92, "error"=>nil, "key"=>nil, "ip"=>"4.6.221.27", "timestamp"=>"2026-01-21 10:25:38", "method"=>"PATCH", "url"=>"http://www.henry.com/", "status_code"=>476, "user_agent"=>"Mozilla/5.0 (Windows; U; Windows NT 6.1) AppleWebKit/531.3.7 (KHTML, like Gecko) Version/5.0.4 Safari/531.3.7"}]
```원본과 사본 구분에 성공했다.
5. 불필요한 필드들을 삭제해주고 필요한 데이터만 들어올 수 있도록 전처리해준다.
# 오픈서치 전용 태그 (복사본에 작업) 특정 데이터 파트 삭제 (전처리 간주)
# 사본 조작 -> 전처리, 오픈서치용 (가공된 데이터만 업로드), s3(원데이터 업로드)
[FILTER]
Name record_modifier
Match processed.logs
# 불필요한 필드 제거
Remove_key topic
Remove_key partition
Remove_key offset
Remove_key error
Remove_key key
# 원 데이터에서 있던 필드
Remove_key user_agent
# 없는 필드를 작성하면? 테스트 (데이터별로 특정 필드가 있을수도, 없을수도 있음)
Remove_key evt
# -------------로그
### 복사본 전처리 후 결과
- 삭제 명령을 내린 필드가 존재 유무에 관계없이 처리 완료 (없으면 무시되는듯)
- 메세지를 간결하게 조정하여 오픈서치용으로 조정
```
[0] raw.logs: [[1768959176.984513559, {}], {"topic"=>"web_logs", "partition"=>0, "offset"=>98, "error"=>nil, "key"=>nil, "ip"=>"38.196.77.76", "timestamp"=>"2026-01-21 10:32:56", "method"=>"OPTIONS", "url"=>"http://lucas.com/", "status_code"=>288, "user_agent"=>"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 5.01; Trident/3.1)"}]
[0] processed.logs: [[1768959176.984513559, {}], {"ip"=>"38.196.77.76", "timestamp"=>"2026-01-21 10:32:56", "method"=>"OPTIONS", "url"=>"http://lucas.com/", "status_code"=>288}]
```topic, partition 등의 필요없는 필드가 사라지고 필요한 데이터만 남게 되었다.
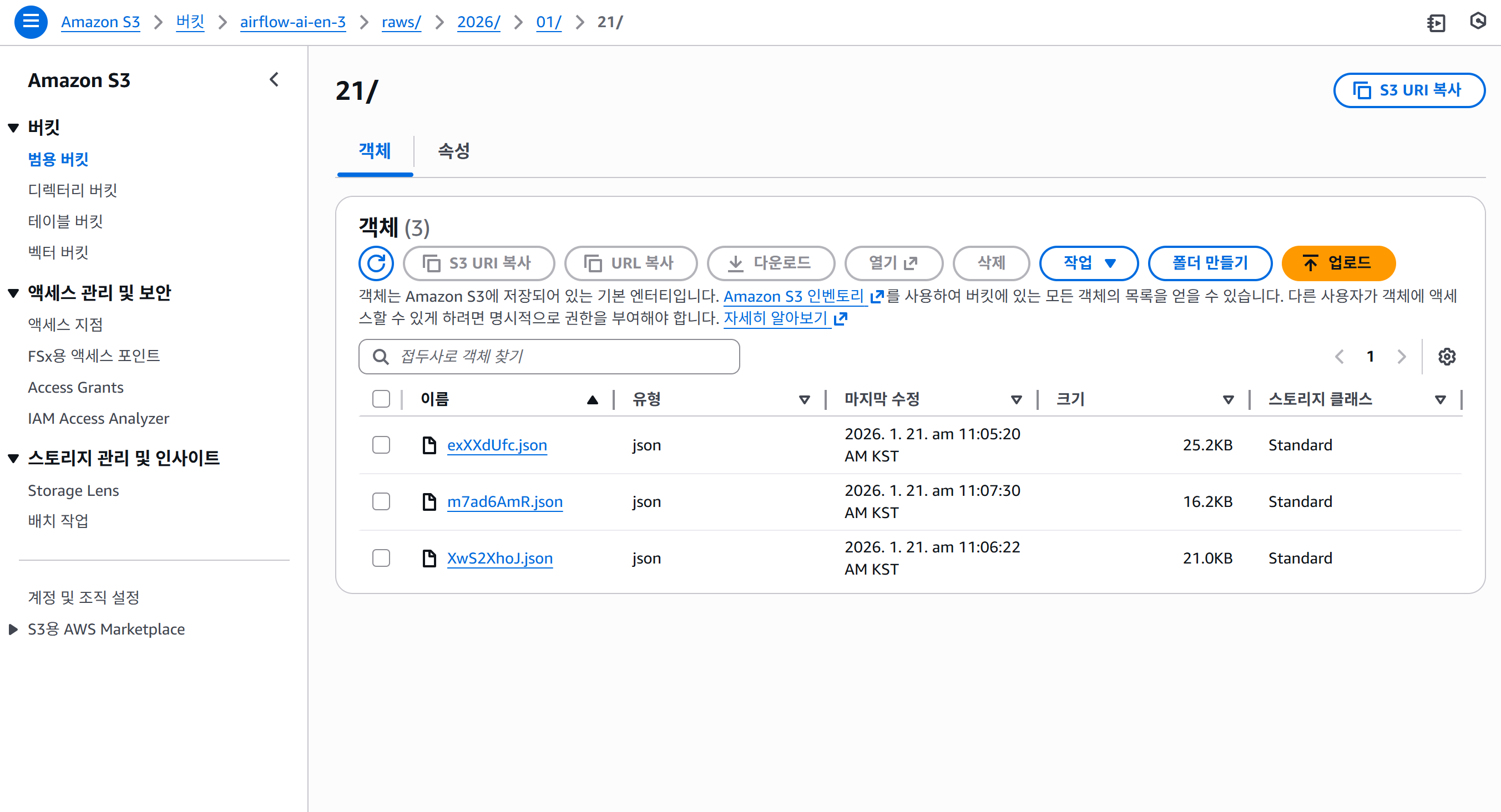
s3에 데이터가 json으로 적재된것을 확인할 수 있다.

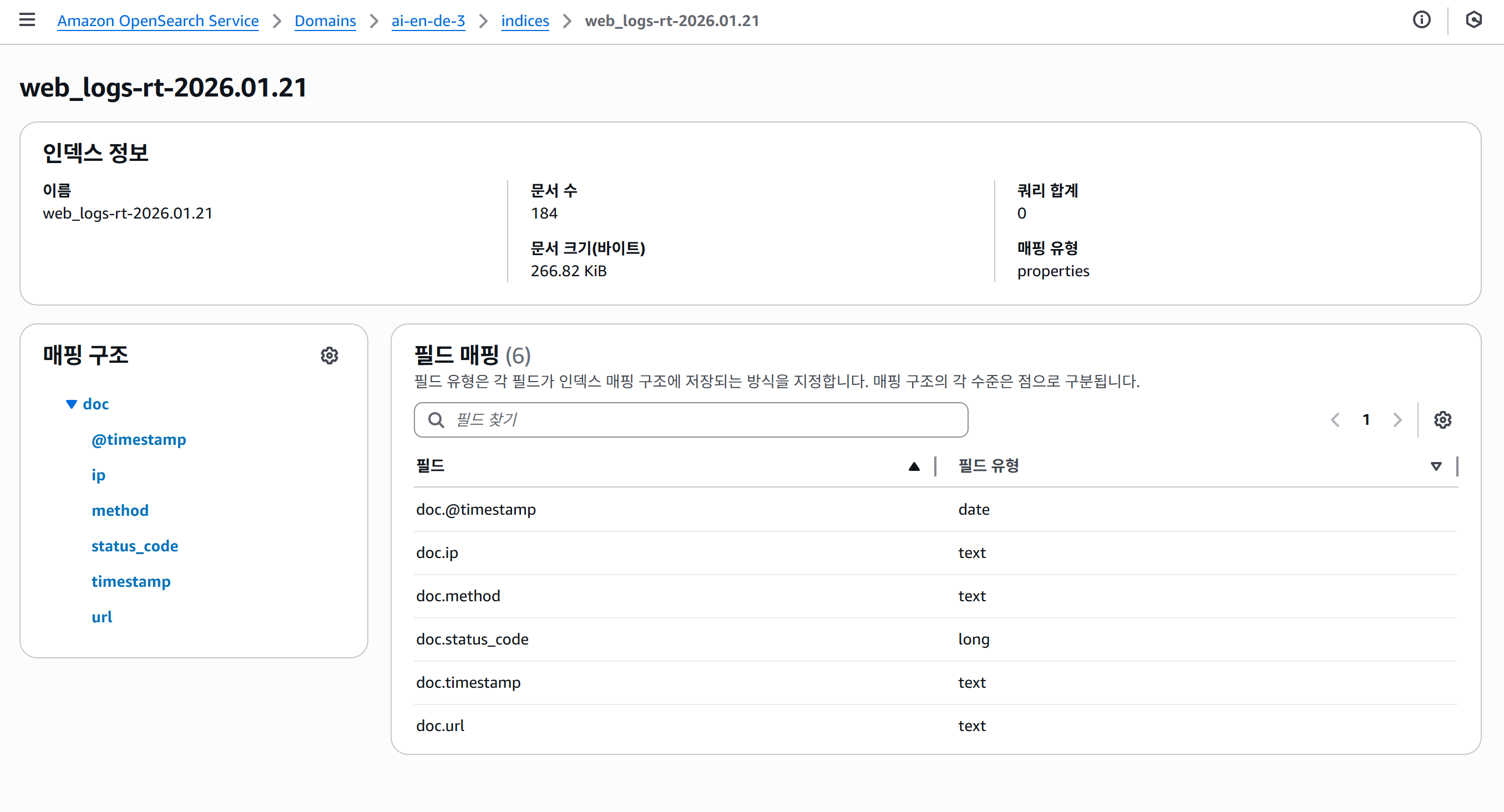
오픈서치에도 데이터가 올바르게 적재되는 모습을 확인할 수 있다.
이렇게 fluent bit를 사용해서 s3와 opensearch에 데이터를 적재하는데에 성공하였다.
다음은 emr이다.
EMR
- EMR + Airflow
- EMR(Elastic MapReduce)
- AWS에서 제공하는 클라우드 기반의 빅데이터 플랫폼
- 대량의 데이터 처리를 위한 Hadoop(하둡), Spark, Hive, …오픈소프프레임웍을 손쉽게 설치, 관리, 운영 등등 서비스
- 특징
- 관리형 서비스 : 복잡한 구성 모두 간편하게 제공
- 확장형(Elasticity) 서비스 : 대량의 데이터양에 따라 탄력적 조절(클러스터의 규모, 운영 범위, ..)
- 비용 효율설 : 사용한 만큼 지불. 서버형, 서버리스, 스팟 인스턴스형
- 스팟 인스턴스형 : 필요할때 생성→사용→해제 (주기 단위가 길면 적절)
- S3 통합형 : HDFS (HaDoop File System) 대체품으로 s3을 저장소로 사용하게 지원
- 하둡의 저장소 ⇒ S3
- 하둡의 연산 ⇒ spark
- S3 + Spark 조합을 사용하여 빅데이터 처리하는 패턴
- Spark : 스칼라언어, PySpark, RSpark 등등 래핑되어 지원
- numpy + pandas + sklearn 등 (데이터 전처리, ML모델학습등 지원)
- Spark : 스칼라언어, PySpark, RSpark 등등 래핑되어 지원
- 실습
- 스팟 인스턴스를 이용하여 Airflow 상에서 DAG 구성
- 더미 데이터(빅데이터) 생성 → s3 저장
- EMR 생성 → 스파크 → s3 데이터 획득 → 전처리 → 결과 s3 저장 → EMR 해제
- 스팟 인스턴스를 이용하여 Airflow 상에서 DAG 구성
- AWS에서 제공하는 클라우드 기반의 빅데이터 플랫폼
- 데이터 규모에 따른 주요 사용 패키지 비교
- EMR(Elastic MapReduce)

하둡, 스파크 비교 요약
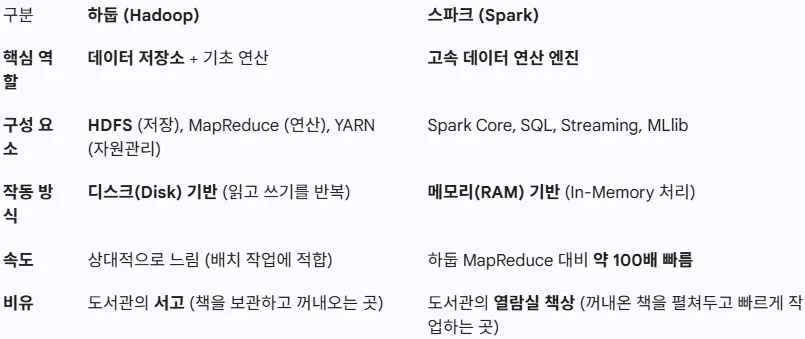
하둡과 스파크를 구분해서 쓰는것이 아닌, EMR을 통해서 두 제품을 모두 사용할것이다.
readme.MD
# 빅데이터(대규모 데이터) 기반 DAG
## PySpark 를 이용한 데이터 전처리
- 구성
L emr
L spark_data_cleaning.py : s3에 위치, 필요시 가져와서 사용
L dummy_big_data_gen.py : 데이터 더미 생성, 노이즈(더럽힌다) 가미하여 데이터 구성, 결과물 s3 업로드(수동) : 리뷰때 s3hook이용해서 airflow에서 더미 구성으로 스케줄 걸기
L dags
L 12_emr_spark.py : 하루에 한번 혹은 6시간 정도에 한번 쌓여진 데이터를 대상으로 데이터 클리닝 작업 진행, 데이터가 빅데이터이므로 spark를 이용하여 대규모 처리 진행. 잠깐만 사용하므로 EMR을 스팟 인스턴스형으로 사용하여 비용을 절감함SPARK를 이용해서 대규모 처리작업을 진행할건데, 이 때 EMR 클러스터를 계속 켜두고 쓰면 비용소모가 너무 심하니까
이를 AIRFLOW를 사용해서 작업할때만 잠깐 키고 다 쓰면 다시 끄게 세팅하는게 이번 실습의 목표이다.
먼저 더미데이터 생성부터 한다.
'''
스파크가 전처리할 더미 데이터를 생성하는 코드
결과물은 raw_data.json 으로 생성
s3://>본인버킷>/raw/dt={{ds}}/raw_data.json
s3://>본인버킷>/raw/dt=2026-01-21/raw_data.json
'''
# 1. 모듈 가져오기
import json
import random
import uuid
from datetime import datetime, timedelta
import time
# 2. 환경 변수
RECORD_COUNT = 1000 # 임시 설정, 전처리 해야하는 데상 데이터 총 계수
# 3. 더미 데이터 생성 함수
def generator_dummy_data_with_noise():
dummy_data=list()
event_types = ['view', 'click', 'purchase','error',None] # 결측 (노이즈 삽입)
os_types = ['iOS', 'Android','Windows', 'Mac', 'Unknown'] # 사용자 단말기 OS
for _ in range(RECORD_COUNT):
record = {
"event_id" : str(uuid.uuid4()), # 해시값으로 무작위 세팅
"user_id" : f"user_{random.randint(1, 500)}", # 사용자는 중복 이벤트 로그 발생
"event_type": random.choice(event_types), # 이벤트
"product_id": random.randint(1000, 2000), # 상품 번호
"price" : random.randint(1000, 100000), # 가격
"timestamp" : (datetime.now()
- timedelta(hours=random.randint(0, 24))).strftime("%Y-%m-%d %H:%M:%S"),
"os" : random.choice(os_types)
}
# 3-2. 노이즈 삽입(혹은 교체)
확률 = random.random()
if 확률 < 0.05:
record['user_id'] = None # 고객 아이디 결측
elif 확률 < 0.1:
record['price'] = -50 # 논리적 오류 (실제 1000~100000)
elif 확률 < 0.15:
record['timestamp'] = "invaild-format" # 형식 깨짐
# 3-3. 데이터 추가
dummy_data.append(record)
return dummy_data
# 4. 함수 호출
if __name__ == "__main__":
data = generator_dummy_data_with_noise()
print(len(data))
# json 저장
with open("raw_data.json", "w", encoding="utf-8") as f:
# 통째로 저장 x , 라인별로 저장 -> json 형태만 저장
for log in data:
# 한줄에 json 1개씩 배치 NewLines Delimited JSON (NDJSON 형식)
f.write(json.dumps(log) + "\n")
# 각자 S3에 수동 저장
s3://>본인버킷>/raw/dt=2026-01-21/raw_data.json이 코드의 포인트는 3개정도다,
1. FOR 문을 사용해서 데이터 1000개를 뽑되, _ 언더바 기호를 사용하여 변수는 신경안쓰고 작업만 1000번 돈다.
2. IF 문으로 확률을 랜덤으로 출력하여 1000개의 데이터에 노이즈(결측치)를 주입한다.
3. JSON파일을 \N으로 나눠서 저장한다.
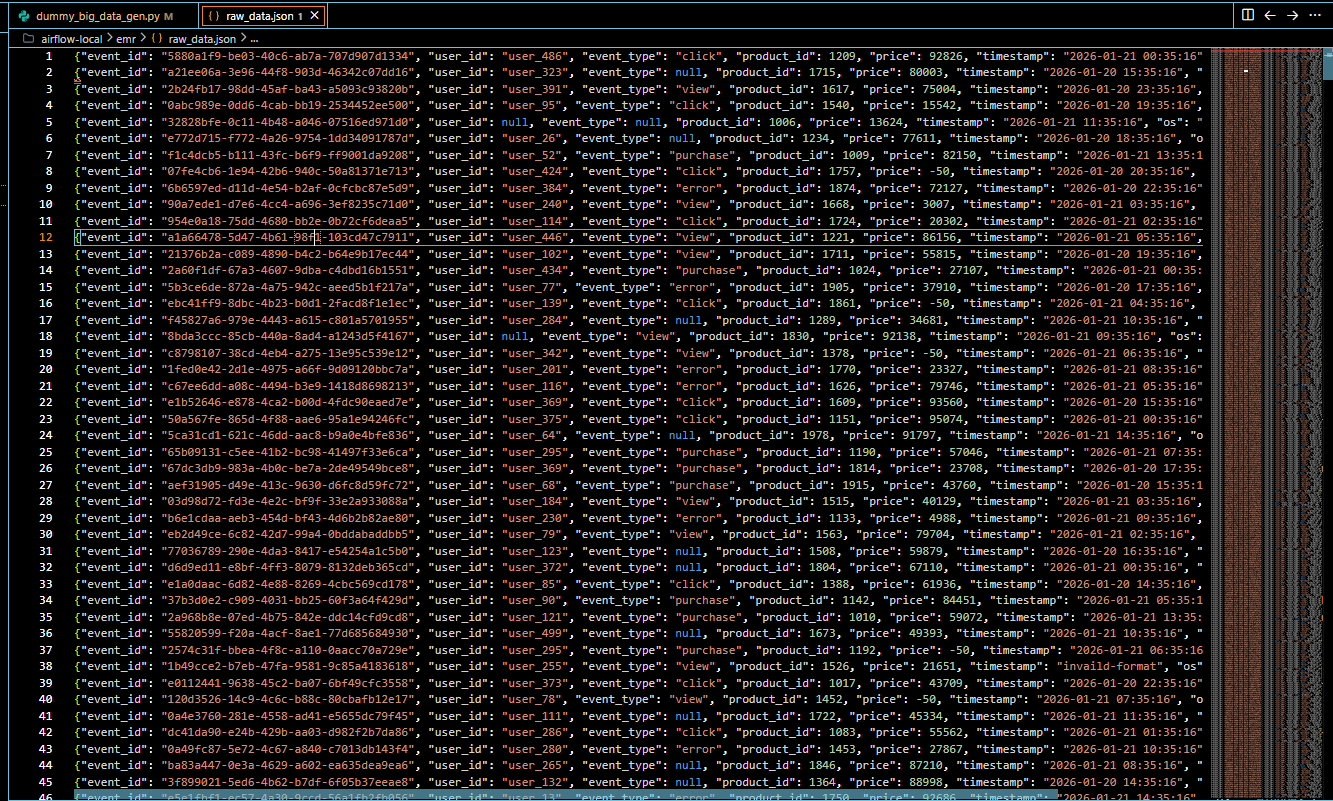
1000개의 값을 가진 raw_data.json이 완성되었다, 이걸 일단 s3에 수동으로 업로드한다.
이제 airflow를 통해서 클러스터가 작동하고 자동으로 꺼지는 과정을 테스트한다.
12_emr_spark.py
'''
절차 : EMR 클러스터 생성 -> Spark 추가 -> 빅데이터 대상 전처리 진행 -> 센서로 완료 감지 -> EMR 종료
'''
# 1. 모듈 가져오기
from datetime import datetime, timedelta
from airflow import DAG
from airflow.providers.amazon.aws.operators.emr import EmrCreateJobFlowOperator, EmrAddStepsOperator, EmrTerminateJobFlowOperator
from airflow.providers.amazon.aws.sensors.emr import EmrStepSensor
import pendulum
from airflow.operators.python import PythonOperator
# 2. 환경변수, 구성(EMR, spark) 설정
BUCKET_NAME = 'airflow-ai-en-3'
EMR_LOG_URI = f's3://{BUCKET_NAME}/emr_logs' # 클러스터 구성 및 해제, 운영간 로그 저장
SPARK_SCRIPT_PATH = f's3://{BUCKET_NAME}/scripts/spark_data_cleaning.py' # 스파크코드 저장
# 2-1. EMR 클러스터 구성 정의(JSON)
# 스팟 인스턴스 설정
JOB_FLOW_OVERRIDES = {
"Name": "Airflow-Automated-EMR-Cluster", # 클러스터명
"ReleaseLabel": "emr-6.10.0", # Spark 3.3.1 포함 버전
"Applications": [{"Name": "Hadoop"}, {"Name": "Spark"}],
"Instances": {
"InstanceGroups": [
{
"Name": "Master node",
"Market": "SPOT", # 비용 절약 (Spot)
"InstanceRole": "MASTER",
"InstanceType": "m5.xlarge",
"InstanceCount": 1,
},
{
"Name": "Core nodes",
"Market": "SPOT", # 비용 절약 (Spot)
"InstanceRole": "CORE",
"InstanceType": "m5.xlarge",
"InstanceCount": 2, # 작업량에 따라 조정
},
],
"KeepJobFlowAliveWhenNoSteps": True, # 단계 완료 후 명시적으로 종료하기 위해 True 설정
"TerminationProtected": False, # 종료 보호 해제
},
"JobFlowRole": "EMR_EC2_DefaultRole", # EC2 인스턴스가 사용할 IAM 역할
"ServiceRole": "EMR_DefaultRole", # EMR 서비스가 사용할 IAM 역할
"LogUri": EMR_LOG_URI, # S3 로그 저장 위치
"VisibleToAllUsers": True,
}
# 2-2. Spark 작업 정의
SPARK_STEPS = [
{
"Name": "Daily Data Cleaning Job",
"ActionOnFailure": "CONTINUE", # 실패해도 클러스터 종료 태스크로 넘어가기 위해 CONTINUE (혹은 TERMINATE_CLUSTER)
"HadoopJarStep": {
"Jar": "command-runner.jar",
"Args": [
"spark-submit",
"--deploy-mode", "cluster",
SPARK_SCRIPT_PATH, # S3에 있는 파이썬 파일 실행
"2026-01-21"#"{{ ds }}" # Airflow 매크로: 실행 날짜(YYYY-MM-DD)를 인자로 전달
],
},
}
]
def _dummpy_task():
print('클러스터 생성 완료 -> 클러스터 삭제 시작')
# 3. DAG 정의
with DAG(
dag_id = "12_emr_spark_v1",
description = "Create EMR -> Spark Cleanning -> Sensor Check -> Terminate EMR",
default_args = {
'owner' : 'de_1team_manager',
'retries' : 1,
'retry_delay' : timedelta(minutes=5)
},
schedule_interval = '@daily', # 하루에 한번 실행
start_date = pendulum.datetime(2026,1,1, tz="Asia/Seoul"),
catchup = False,
tags = ["EMR", "spark"]
) as dag:
# 3-1 오퍼레이터 정의
# task 1 EMR 클러스터 생성 -> XCom을 통해서 return_value라는 키 값을 추출하면 -> 클러스터 id가 됨
create_cluster = EmrCreateJobFlowOperator(
task_id = "create_cluster",
job_flow_overrides = JOB_FLOW_OVERRIDES,
aws_conn_id = "aws_default",
)
dummpy_task = PythonOperator(
task_id = "dummpy_task",
python_callable = _dummpy_task
)
# task 2 spark 이용한 데이터 클리닝
add_steps = EmrAddStepsOperator(
task_id = "spark_cleaning_task",
job_flow_id = "{{task_instance.xcom_pull(task_ids='create_cluster', key='return_value')}}",
aws_conn_id = "aws_default",
steps = SPARK_STEPS,
)
# task 3 task2 작업에 대한 완료 센서를 통해서 감지(대기)
# task 4 EMR 클러스터 해제
terminate_cluster = EmrTerminateJobFlowOperator(
task_id = "terminate_cluster",
# 직전에 생성된 emr 클러스터 id값 세팅 -> 삭제 대상을 특정할 수 있음
# XCom은 게시판 처럼 고려 -> 어떤 task에서 등록만 되어있으면 몇단계 이후에도 접근은 가능함
job_flow_id = "{{task_instance.xcom_pull(task_ids='create_cluster', key='return_value')}}",
aws_conn_id = "aws_default",
trigger_rule = 'all_done' # 앞의 task에서 실패해도 무조건 이 task는 작동한다(실행한다)
)
# 3-2 의존성 설정
create_cluster >> dummpy_task >> add_steps >> terminate_cluster
spark 부분은 사실 강사님이 그대로 가져가라고 하셔서 확실한 디테일은 파악이 조금 어렵다.
이 DAG의 포인트는 클러스터를 생성하고, 꺼지는건데 그 부분이 TASK 1~ 4에 포함되어있다.
코드를 작성하고 AIRFLOW에서 DAG을 실행시키면

자동으로 클러스터가 켜졌다가 꺼지는것을 확인할 수 있다.
다음 과정
-> S3상에 SPARK 코드가 입력된 파이썬 파일을 저장하여 SPARK 과정까지 작동시킨다.
TASK3에 있는 내용이 SPARK 파일이 저장되어있는 경로를 따라가는것이다.
-> S3상에 SPARK 코드가 올라가는 과정또한 DAG으로 구성하여 자동화하는것이다.
오늘의 수업은 여기까지
'ASAC-SK플래닛 T아카데미 데이터 엔지니어' 카테고리의 다른 글
| 26.01.26~27 | 76~77일차 [코딩테스트 특강] (0) | 2026.02.02 |
|---|---|
| 26.01.22~23 | 74~75일차 [spark 마무리 | CDK | 미니프로젝트 시작] (0) | 2026.01.23 |
| 26.01.20 72일차 [kafka connect | logstash 사용 s3,opensearch 적재] (0) | 2026.01.20 |
| 26.01.19 71일차 [Airflow | ELK_Elasticsearch, AWS OpenSearch | Kafka_실시간 스트리밍 데이터 대용량 처리 , 개요, 구성, 실습] (1) | 2026.01.19 |
| 26.01.16 70일차 [Airflow | ELK_log_generator, reader] (0) | 2026.01.18 |