오늘은 머신러닝 지도학습 분류 성능평가, 학습, 최적화에 대한 수업을 진행했다.
양 너무 많다...
어제 수업에 이어서 kaggle playground 고양이 분류 모델 예측파트부터 이어서 진행했다.

이전과는 다르게 단순한 분류가 아닌 예측 확률을 리턴해야 하기 때문에 predict_proba 함수를 사용해서 확률을 return한다.
그 확률은 76퍼센트로, 입상에는 아직 못 미치는 확률이다.
따라서 다음 과정들을 익히면서 확률을 올려줄것이다,.
머신러닝 지도학습 분류 _ 성능평가
개요
- 머신러닝 성능평가
- 분류 : 혼동행렬 (오차행렬) 기반
- 정확도, 재현율, 정밀도, 조화평균, auc, roc, 커스텀 지표(기업, 대회에서 룰로 제공)
- 회귀 : 손실함수 (오차율) 기반
- rmse, mes, . . ,
- 군집 : 앱실론 계수(대표적)
- 분류 : 혼동행렬 (오차행렬) 기반
목적
- 의미
- 알고리즘 학습 후 모델의 성능을 평가하는 도구/지표/방법/기준 (matric)
- 기반 자료
- 혼동(오차) 행렬(Confusion matrix)
- 중요점 : 내용 | 상황 | 시나리오 등에 감정이입 x , 기계적 | 객관적 체크
- 혼동(오차) 행렬(Confusion matrix)
혼동 행렬 구성
- 4개 요소를 평가 조합으로 사용
- 공통요소 (2개)
- Positive -> P, 긍정
- Negative -> N, 부정
- 판단요소 (2개)
- True -> T, 예측값과 실제값이 일치
- False -> F, 예측값과 실제값이 불일치
- 조합
- TP, TN, FP, FN -> 4가지 조합
- 공통요소 (2개)
예시
- 명제
- 암이 있다(악성 종양이 있다.) : P
- 암이 없다(양성 종양(지방종)이 있다.) : N
- 실제로 암이 있는건 부정적인 내용이지만 있다는 사실만 보면 긍정이기 떄문에 P이다.
암이 있다고(없다고) 에측하였는데, 실제 암이 있(없)었다
- TP
암이 있다고 에측하였는데, 실제 암이 있었다
- TN
암이 없다고 에측하였는데, 실제 암이 없었다
- FP
암이 있다고 에측하였는데, 실제 암이 없었다
- FN
암이 없다고 에측하였는데, 실제 암이 있었다
평가지표
- 데이터별, 요구사항별로 중요도가 달라질 수 있음
(*)정확도 : 가장 일반적
- accuracy -> acc
- 식
- 정확도 = (실제값과 예측값이 동일한 개수) / (예측한 총 개수)
- 20만건을 예측했고 그 중 x개를 맞췄다
- 혼동행렬 성분으로 계산식
- acc = (TP + TN) / (TP + TN + FP + FN)
- 예측이 현실에 부합되는 확률
- % 로 표현 (백분율)
- 학습된 모델이 한번도 접하지 못한(경험하지 못한) 데이터에 대해서 얼마나 정확하게 예측하는가를 가늠하는 지표
정밀도
- Precision -> P
- 암이라고 진단한 모든 케이스 중에서, 실제 암이 존재했던 비율
- 암을 잘 진단하는 병원
- 식
- P = (TP) / (TP + FP)
재현율, 민감도
- Recall or Sensitive -> R
- 예시 : 병원 특성
- 해당 병원은 암 환자를 잘 찾아낸다
- 혼동행렬 성분으로 계산식
- (실제 암을 정확하게 진단한 건수) / (실제 암이 존재했던 케이스의 총 수 )
- R = (TP) / (TP + FN)
- 참 긍정 비율, TPR
- 거짓 긍정 비율 FPR = 1 - TPR = 1 - R
- 참고
- 참 긍정 비율, 거짓 긍정 비율 -> ROC / AUC 계산할때 사용됨
특이성(특이도)
- specificity -> S
- 병원 예시
- 실제 암이 없는 전체 데이터에서, 암이 업다고 실제로 맞춘 비율
- 식
- S = (TN) / (TN + FP)
- 참 부정 비율 = TNR
f1-score
- 조화평균
- 용도
- 모델의 성능 평가를 하고싶은데, R을 쓸지, P를 쓸지 애매하다,
- 조화롭게 사용 <-> 둘 다 써라
- 모델의 성능 평가를 하고싶은데, R을 쓸지, P를 쓸지 애매하다,
- 용도
- 병원예시
- 정밀도와 재현율을 조화롭게 평가하고싶다.
- 식
- f1-score = 2PR / ( P + R ) = 2 / (1/P) + (1/R)
ROC커브, AUC 값
- 여러개의 모델을 동시 비교 시 종종 등장, 사용
- ROC 커브
- 2D 좌표계로 표현
- X축 : 참 긍정 비율
- Y축 : 거짓 긍정 비율
- 차트 -> 점점 참 긍정 비율이 커지게 구성 -> 모델 성능 향상되는중
- 여러 모델 비교 시
- 곡선하 면적을 계산하여 비교 -> 곡선(그래프)의 하위 (밑으로) 차지하는 면적 계산
- AUC(정확도)값을 추출해서 비교함
- 가장 높은 값을 가진 모델이 최적 모델임
정리
- 타겟값으로 예측
- predict()
- 정확도, 정밀도, 재현율, ...
- 타겟값이 나올 확률(proba)로 예측
- predict_proba(), - predict_log_proba()
- ROC, AUC로 평가
머신러닝 샘플 데이터로 ROC,AUC 평가 진행
머신러닝 연습용 데이터
- sklearn 패키지
- fetch_xxx
- 용량이 큼, 요청시 다운로드됨
- load_xxx
- sklearn 설치 시 같이 설치됨, 저용량
- make_xxx
- 더미 데이터 구성 시 사용
- 피처 수, 정규분포(평균, 표준편차등) 세팅
- fetch_xxx
간략하게 코드 진행 (절차 심플)
1. 모듈 가져오기로 필요한 항목들을 가져온다.
2. sklearn에 기본으로 있는 데이터셋_iris를 가져오고 담아준다.
# 3. 데이터 확인
print(raw_data.DESCR)
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
.. dropdown:: References
- Fisher, R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Mathematical Statistics" (John Wiley, NY, 1950).
- Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.
(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System
Structure and Classification Rule for Recognition in Partially Exposed
Environments". IEEE Transactions on Pattern Analysis and Machine
Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions
on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II
conceptual clustering system finds 3 classes in the data.
- Many, many more ...데이터는 (150,4) 로 구성되어있고 각 컬럼명과 종속변수가 함께 있다.

데이터를 파악한다, 피처데이터는 2d형식으로 배열이고 타입은 부동소수 float형식이다.
타겟 = 정답 레이블은 종으로 구성되어있다.

데이터 전처리가 가능한 데이터프레임형식으로 수정시켜준다,
그 이후 정답을 맞출 수 있도록 타겟 컬럼도 추가해준다.
모델 구축
# 1. 알고리즘 선정 - 여러개 활용
# 이진분류용, 선형회귀열, 로지스틱회귀
from sklearn.linear_model import LogisticRegression
# 데이터가 텍스트인 경우 사용
from sklearn.naive_bayes import GaussianNB
# 서포트벡터머신, 기본 모델, 이진분류용
from sklearn.svm import SVC
# 결정트리, 이상형월드컵, 이진분류 | 다중분류, 앙상블 계열의 베이스 모델
from sklearn.tree import DecisionTreeClassifier
# 앙상블의 대표 알고리즘, 배깅계열, 동일 알고리즘 n개를 조합하여 사용, 이진분류 | 다중분류
from sklearn.ensemble import RandomForestClassifier
이전과 다르게 여러개의 알고리즘을 사용해서 분석할 예정이다.
models = {
# "알고리즘명":(차트상 선의 모양, 알고리즘 객체)
"LogisticRegression" : ('-', LogisticRegression()),
"GaussianNB" : ('--', GaussianNB()),
"SVC" : ('.-', SVC(probability=True)), # 특정값의 확률로 표현
"DecisionTreeClassifier" : (':',DecisionTreeClassifier(max_depth=5)),
"RandomForestClassifier" : ('-',RandomForestClassifier(n_estimators=10,
max_features=1,
max_depth=5))
}딕셔너리의 형태로 알고리즘들을 넣어준다, 그래프에 표출될 차트상 선의 모양도 지정해준다.
알고리즘에 있는 인자들의 값은 기본이고 필요시 마우스를 올려보고 인자 기본값, 기능 등 파악하여 사용하면 된다.
# 조건
# 정답 데이터를 정답 1이 맞으면 True, 아니면 False 조정 -> 1일 확률을 사용하도록 단순화
X = df.iloc[ : , :-1] # 피처 데이터만 적용
y = df.target # 정답 데이터만 적용
# (150,4) , (150,)
X.shape, y.shape불리언 인덱싱을 통해서 원래는 정답은 없지만 1을 정답으로 학습시키도록 변수를 지정해준다.


데이터를 분할한 코드와 이유.
1. 전체 150개의 데이터중 학습용 데이터 = train 과 시험용 데이터 = test 데이터를 나눠주어야 한다.
2. 테스트데이터까지 학습해버리면 모델은 정답을 100% 맞추기 때문이다.
3. stratify = y / 데이터를 75:25로 나누는데 비율이 다르면 학습 데이터에 한 정답이 50개 나머지 정답이 10개 이렇게 갈 수도 잇어서 그 비율을 유지해주는 옵션이다.
4. 75:25 = 국룰 비율이지만 절대값은 아니다.
from sklearn.metrics import roc_curve, auc
# 모델 학습 -> 예측 -> 평가 -> roc, auc 시각화 및 값 출력
for al_nm, (line_style, model) in models.items():
# 알고리즘 이름, 선 모양(line_style), 알고리즘 객체 각각 추출되도록 추가 조정 -> for문에서 소괄호로 한번 감싸줬음
# print(al_nm, line_style, model)
# 1. 학습
model.fit( X_train, y_train)
# 2. 예측
y_pred_proba = model.predict_proba(X_test)
# 1(긍정)일 확률만 추출
# print(y_pred_proba)
y_pred_t = y_pred_proba[ :, -1]
# 3. roc 커브
fpr, tpr, _ = roc_curve(y_test.values, y_pred_t)
# 4. 차트 그리기
plt.plot(fpr, tpr, line_style, label=al_nm)
# 5. 결과 정리 -> 수치로 나옴
print(al_nm, auc(fpr,tpr))
plt.legend()
plt.xlabel('False Posivice Rate')
plt.ylabel('True Posivice Rate')
plt.show()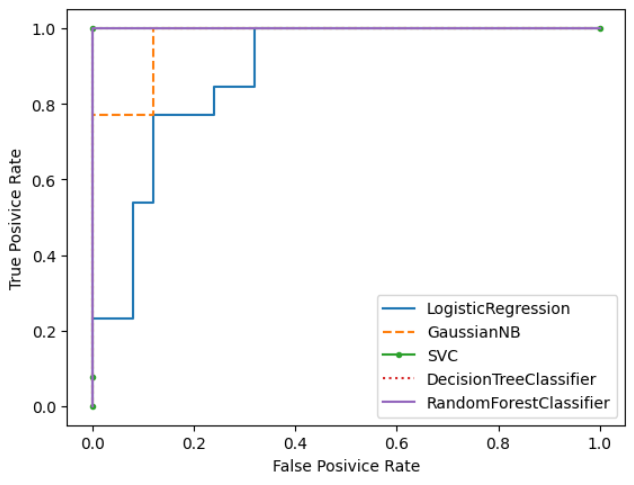

아우 하나하나 설명 보는데 넘 어렵다
긍정일 확률만 추출하는 부분이 이해가 잘 안갔지만 로그를 보면
[ 0.xxx , 0.xxxx] 이다.
여기서 정답 부분의 인덱스가 -1이니 -1의 값만 추출해서 그래프에 적용하는것이다.
그 다음으로는 그래프 그리는 문법이다!
이렇게 성능평가끝
다음은 학습이다.
머신러닝 지도학습 분류 _ 학습
개요
- 학습시 사용되는 데이터별 용도
- 훈련 데이터
- 모델(알고리즘 : 머신러닝, 인공신경망 : 딥러닝,LLM ) 학습(훈련) 용도
- 훈련을 통해 파라미터를 최적화 수행
- 주로 train_test_split()을 통해 획득
- 모델(알고리즘 : 머신러닝, 인공신경망 : 딥러닝,LLM ) 학습(훈련) 용도
- 검증 데이터
- 모델 성능 조절 용도
- 과대적합(over fitting), 과소적합 판단용
- 훈련시 내부적으로 판단하고 조정
- 훈련시 사용하는 것은 아님 -> 다른 조합(교차검증 절차에서 확인)에서는 훈련용으로 사용될 수 있음
- 교차검증 (CV)
- 파라미터명에 CV가 들어가면 교차검증하겠다는 의미 => 세트수(홀수)를 의미함
- CV = 3, 5, 7, 9
- 테스트 데이터
- 모델의 성능 평가 용도
- 훈련 데이터
교차검증 (K-fold)
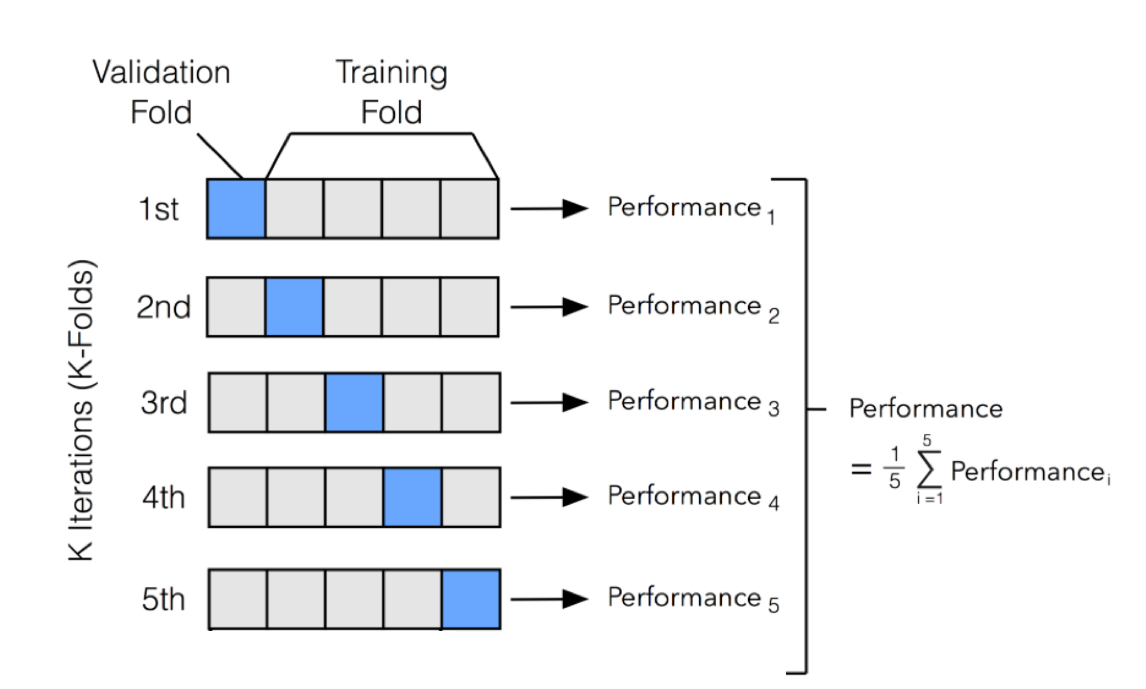
학습을 통해서 정확도를 올리는 부분이다, kfold 외우기
Kfold 시뮬레이션
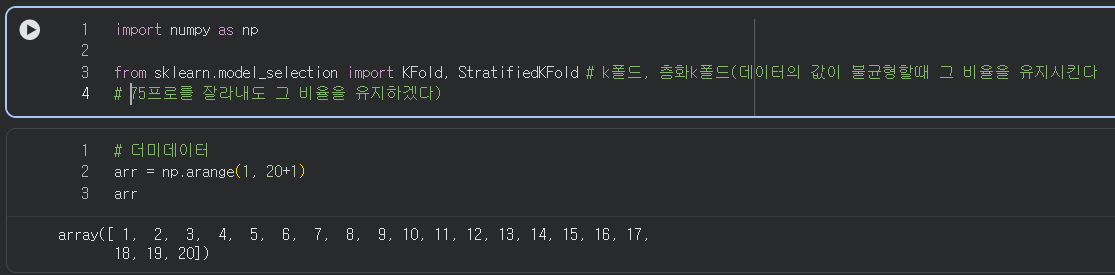
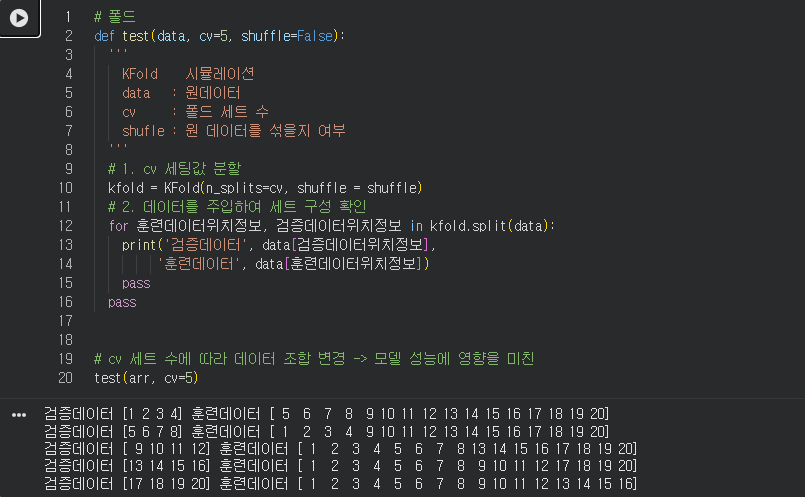
위의 이미지를 보여주기 위한 더미데이터이다.
1~20 까지의 숫자를 담은 배열이 다섯조각으로 나뉘어서 훈련되고 돌아가는것을 확인할 수 있다.
층화 KFold 시뮬레이션
- kfold 기능
- 데이터 내부의 고유값의 구성 비율을 유지

이전에 사용했던 코드에서 구성비율을 확인하기 위해서 이름을 바꿔봤다.
악성이 5개, 양성이 45개이다.
랜덤하기 때문에 어떤 세트에서는 악성이 없을수도 , 있을수도 있다.

악성의 위치를 보기 쉽게 인덱스?를 붙여줬다.
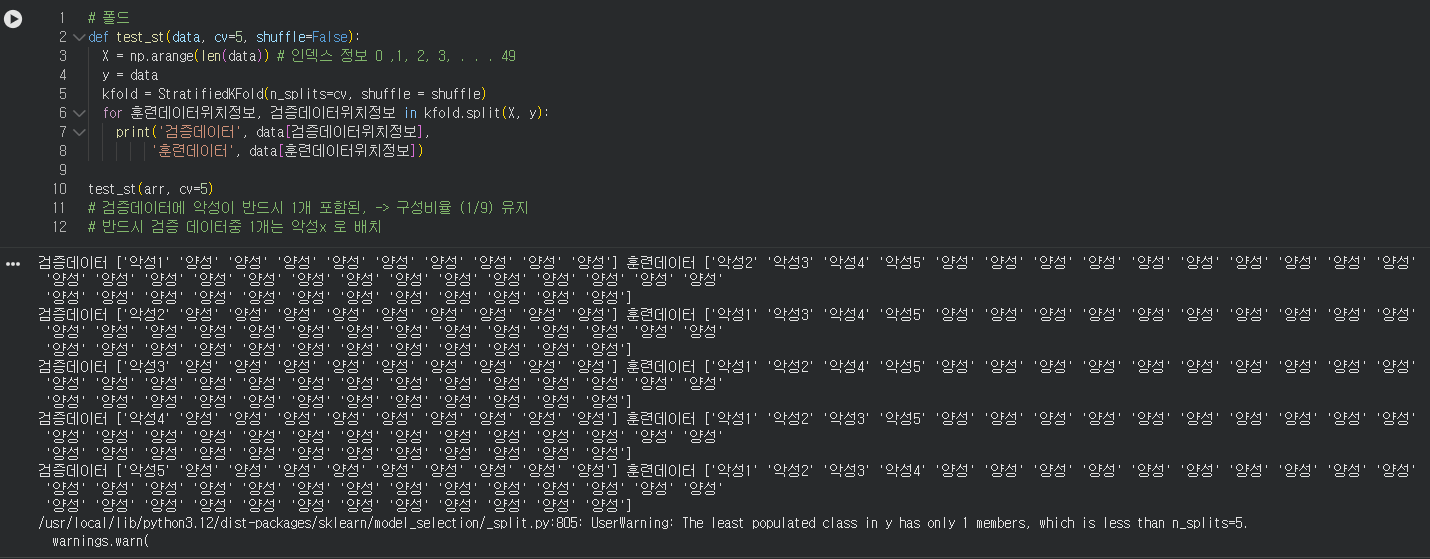
구성비율의 키포인트는 5번 코드에 있는 StratifiedKFold 옵션이다.
옵션을 추가해줘서 모든 세트마다 검증 데이터에 악성이 들어가서 데이터의 구성비율을 유지하는 내용을 가지고 있따.
데이터들의 결과가 50:50이 아니고 이렇게 몰려있을 경우엔 '층화'KFold를 이용해서 구성비율을 맞춰줘야 올바른 학습이 가능하다.
마지막은 최적화다.
개요
- 베이스라인 구축 이후, 모델 성능을 높이기 위해 진행되는 절차
- 데이터 추가 확보
- 피처엔지니어링 (데이터 전처리 포함) 전략 수정
- 모델 교체
- 다른 알고리즘 사용
- 보팅 행위(n개 알고리즘 사용, 다수결/득점률로 판정하는 전략) -> 집단지성
- 마지막에 끌어올리는 전략 (1등, 2등 알고리즘을 1:1로 블렌딩 -> 총 확률값으로 판정)
- 절차적 모델 최적화 (모델 1개)
- 하이퍼 파라미터 튜닝
- 파이프라인
- 데이터 전처리 + 학습
- 베이지안 최적화 (서드파트 패키지)
- AutoML을 활용(종합적 최적화 수행)
- 알고리즘의 원리를 몰라도 최적 알고리즘 획득 가능함 (나와있는 모든 최적화 기법 총동원)
- 본질은 데이터 처리에 달려있음
- 마지막의 마지막 -> 랜덤시드 조정 (찍기 신공)
베이스라인 구축 (필요없는 부분 생략)
- 기본 모델로 진행
연구목표
- 유방암 진단 (악성, 양성)하는 모델 구축
- 사람의 인지 능력으로 판정하는 정확도가 낮아서, AI에게 훈련시켜 이 정확도를 높이고자 한다
- 이진 분류
데이터 획득

sklearn.datasets에 있는 기본 데이터 breast_cancer 데이터를 가져온다.
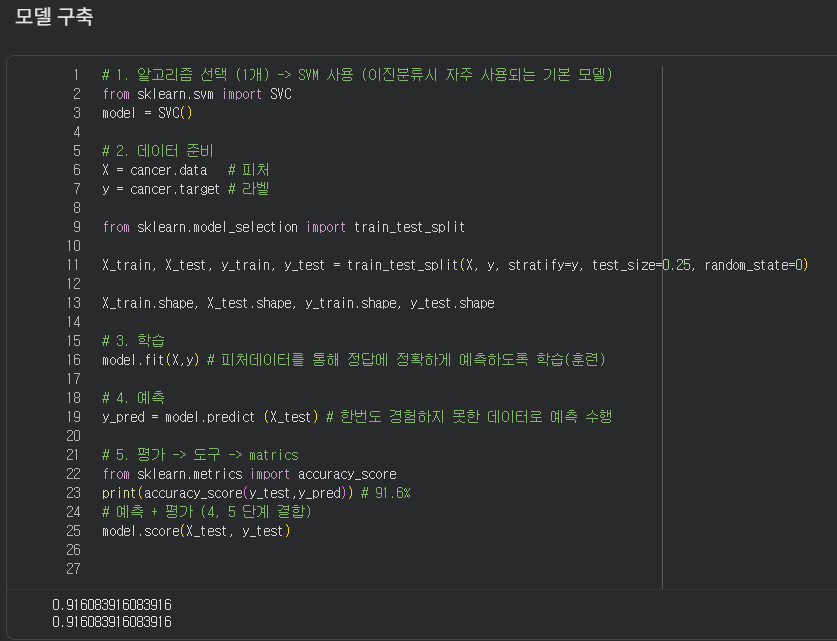
빠르게 모델 먼저 구축해준다, 모델은 이제 많이 구축해봤으니 이전 수업내용을 참고하면서 구성할 수 있다.
평가까지 한 결과 이모델의 정확도는 약 91%이다.
최적화
- 91.6%의 성능을 가진 모델을 96%까지 향상(목표)
- 방법
- 하이퍼 파라미터 튜닝
- 데이터쪽은 관여 x, 모델 자체를 향상
- 데이터 일부 조정(전처리)
- 파이프라인 활용 + 하이퍼파라미터 튜닝
- 기타
- 랜덤서치, 베이지안 최적화 활용
- AutoML 활용
- 하이퍼 파라미터 튜닝
하이퍼 파라미터 튜닝

- 개요
- 알고리즘별로 모델 성능에 영향을 미치는 파라미터가 존재함(= 하이퍼 파라미터)
- 도구
- 교차(격자 => Grid)
- GridSearchCV :
- 파라미터값을 교차적용(조합)
- CV를 이용하여 교차검증 학습 적용
- 단점
- 최적의 후보값 개발자가 선정(찍기)
- 후보가 많으면 시간이 늘어남 (조합이 많아지므로)
- RandomiizedSearchCV
- 최적 파라미터 후보값을 LOW ~ HIGH 사이에 랜덤으로 선택됨
- low, high는 선택해야함(개발자)
- 난수 시드 영향을 미침 (개발자 선택)
- 상대적 시간이 더 소요됨
- 의외성을 높이기 때문에 상대적으로 성능향상 기대 | 하지만 복불복
- GridSearchCV :
- 써드파트
- 베이지안 최적화
- 가장 성능이 좋은것으로 평가됨
- AutoML 내부에서 사용됨
- 절차
- 최초는 랜덤 서치 -> 학습 -> 사전정보 획득 -> 확률 추정 -> 최적값을 찾음
- 베이지안 최적화
- 기타
- 함수형 제공 (잘 안씀)
- 교차(격자 => Grid)
GridSearchCV
from sklearn.model_selection import GridSearchCV
# 하이퍼 파라미터의 후보값 제시 => 총 10 (5 * 2) 개의 조합
param_grid= {
# 기본값 좌우로 특정 배수 혹은 1/배수 로 값을 배치
'C' : [ 0.001 , 0.1 , 1 , 10 , 100],
'gamma' : ['scale', 'auto']
}
# 알고리즘 1개에 대한 튜닝
# 총 학습 회수 = 5 * 2 * 5(cv) = 50회의 서로 다른 조합으로 학습이 진행됨(경우의수만)
# 총 10개의 조합의 결과를 비교, 1개의 조합에서는 5번의 교차학습 진행됨
grid = GridSearchCV( SVC(), param_grid , cv=5)
최적화를 위한 하나의 도구이다
그리드서치의 하이퍼파라미터를 여러개 넣어준다, 그렇게 하면
각 하이퍼파라미터별로 조합해보면서 얘가 어떤 파라미터가 가장 효율이 좋은지 돌려준다,
인자가 5개 * 2개 그리고 아까 진행햇던 cv가 5개이니 총 50번의 교차학습을 진행한다.
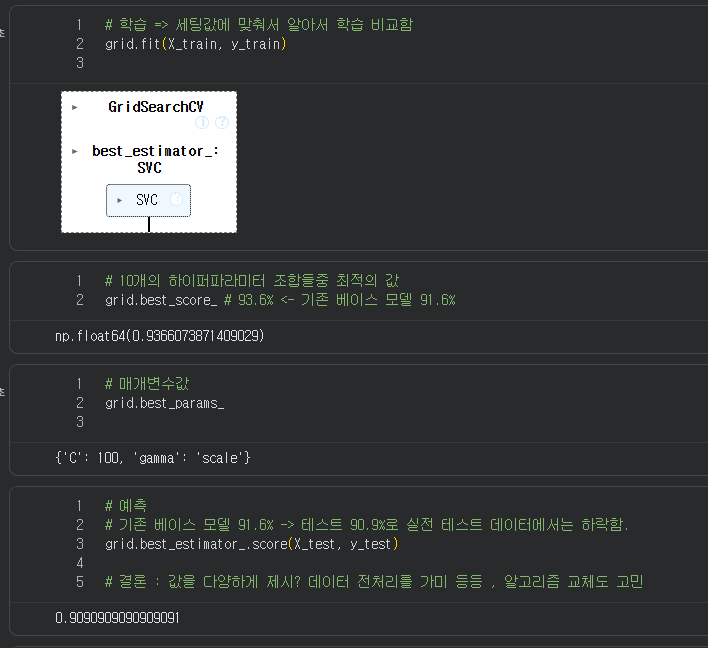
현재 grid 변수는 50번의 교차학습을 진행한 클래스다.
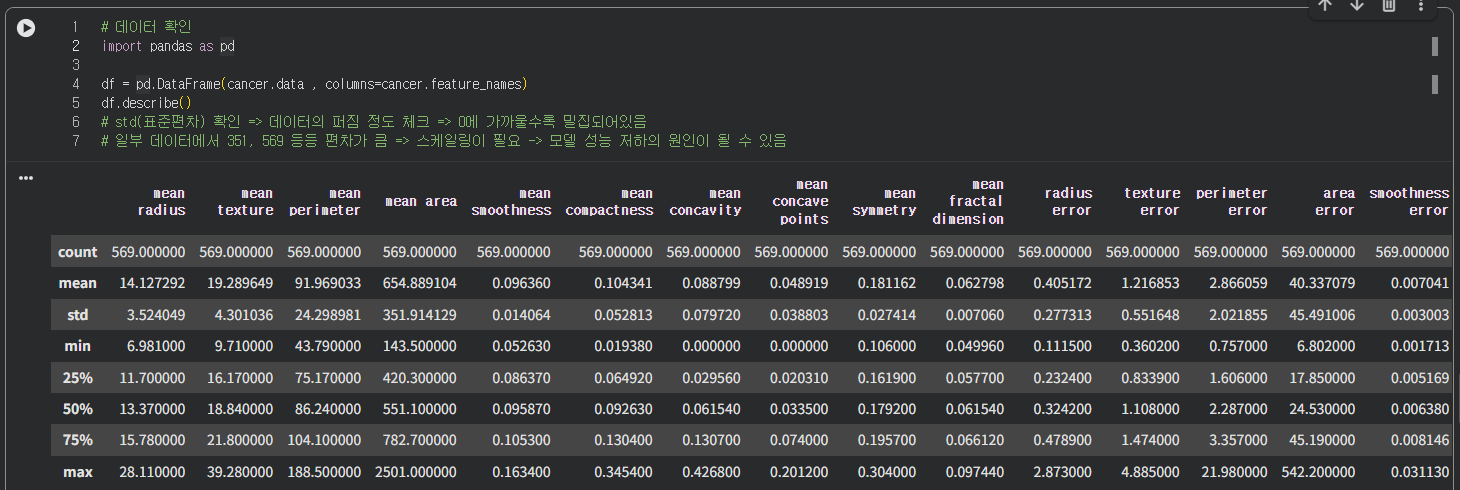
cancer 데이터프레임을 구성했다. 데이터 확인결과 표준편차에서 엄청 큰 값들이 있어서 스케일링이 필요할 것 같다.
그래서 이후에 배울 내용이지만 파이프라인 구축을 해서 전처리와 파라미터 튜닝까지 한번에 작업하도록 실습을 진행한다.
파이프라인 구축 (활용)
- 데이터 전처리 + 하이퍼파라미터 튜닝 연결
- 따로 진행하면 CV에서 문제 소지 있음

파이프라인 구축 라이브러리 가져온 후
minmax스케일러와 svc 알고리즘을 하나로 묶어서 pipe에 담아준다
이제 pipe는 스케일링과 svc알고리즘을 둘 다 수행하는 클래스이다.
이 둘의 차이는 이름 설정해주는거 하나뿐
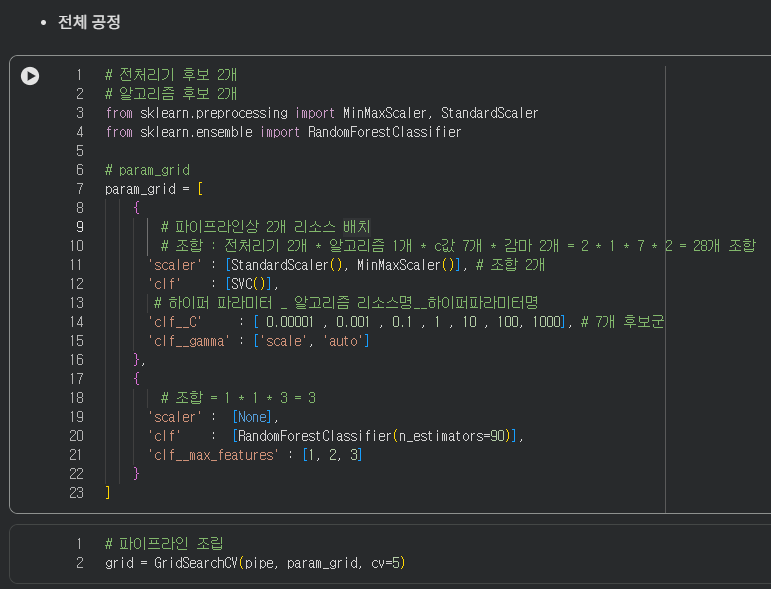

주석 추후 첨부
'ASAC-SK플래닛 T아카데미 데이터 엔지니어' 카테고리의 다른 글
| 25.12.09 44일차 [머신러닝_지도학습_회귀] (0) | 2025.12.10 |
|---|---|
| 25.12.08 43일차 [머신러닝 분류 최적화, 베이지안 최적화 | 머신러닝 주요 알고리즘, 결정트리,앙상블, 스태킹] (1) | 2025.12.08 |
| 25.12.04 41일차 [ 머신러닝 지도학습 분류 캐글 playground 경쟁분야] (0) | 2025.12.04 |
| 25.12.03 40일차 [ 머신러닝 전체 플로우 진행, 간단한 모델 구성 | 머신러닝 지도학습 분류 캐글 playground 경쟁분야] (1) | 2025.12.03 |
| 25.12.02 39일차 [ 머신러닝 중요개념 이해 | 개요, 모델 학습절차 -> 인공지능 모델 학습 워크플로우 5단계 | 머신러닝 전체 플로우 진행, 간단한 모델 구성] (0) | 2025.12.02 |