오늘은 머신러닝 지도학습 분류 파트를 마무리 한 후
머신러닝 지도학습 회귀 파트를 수업했다.
회귀또한 캐글에 있는 문제를 한번 풀어보는 형식 또한 진행했다.
머신러닝 지도학습 _ 회귀
정의
- 자연현상 (사회현상)등에서 다양한 변수들 사이에 관계를 모델링하는 방법
- 과외 시간이 수능 성적에 미치는 영향
- 서울 집값 예측 -> 수치 - 연속형
- 따릉이 수요량 예측 -> 수치 - 연속형
- 데이터 구성
- 독립변수(피처) : 영향을 주는 변수
- 종속변수(레이블) : 영향을 받는 변수
- 독립변수와 종속변수간의 관계(식)을 모델링 하는 방법
- 학습을 통해서 모델이 완성됨(러닝,학습)
- 해당 모델을 통해서 예측수행
- 예측은 정확하게 맞출 수 없다 -> 근사하게 맞춘다 -> 오차(에러)를 최소로 하게 학습하는것이 목표
- 정답은 수치형-연속형 데이터임
구성원
- 독립 변수
- 개수 기준 분류
- 단순 선형 회귀
- 독립 변수(x) 1개, 종속 변수(y) 1개
- 두 변수간의 관계식
- y = w0 + w1x
- 1차 함수 (선형)
- 핵심
- w0, w1 만 알면, 두 변수간의 관계를 정의할 수 있다.
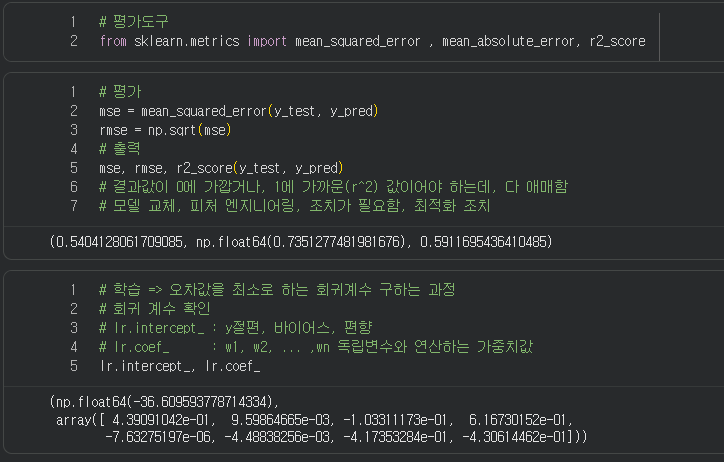
- 학습
- 최적의 w0, w1을 찾아가는 과정
- 최적이란, 오차값이 최소가 되는 값을 찾으면 이것을 최적의 값이라 함
- 오차값이 0에 가까울수록 성능 좋은 모델
- 학습 -> 평가 -> w0, w1 조정 -> 학습 -> 평가 -> w0, w1 조정 -> ... -> 학습 종료(기준 도달하면)
- 다중 선형 회귀
- 독립 변수 n개, 종속 변수 1개
- 두 번수간의 관계식
- y = w0 + w1x1 + w2x2 + ... + wnXn
- 단순 선형 회귀
- 개수 기준 분류
- w
- 회귀에서 w는 회귀계수라고 부름
- 1차 함수에서는
- w0:y절편
- w1:기울기
- 딥러닝에서는 파라미터라고 부름
- w0 : 편향, bais
- w1 : 가중치, weight
- 1차 함수에서는
- 회귀에서 w는 회귀계수라고 부름
- 회귀계수
- 선형 : 단순 선형 회귀, 직선
- 비선형 : 다중 선형 회귀, 곡선
RSS
- Residual sum of square (잔차제곱합)
- 비용함수
- (실제값 - 예측값)^2 한 후 총합
- rss값이 최소가 되도록 회귀계수 w0, w1을 조정하는것이 => 학습

회귀 - 베이스라인 구성
- 데이터
- 캘리포니아 집값(연속형)
- 목표
- 집값 예측하는 모델 구축

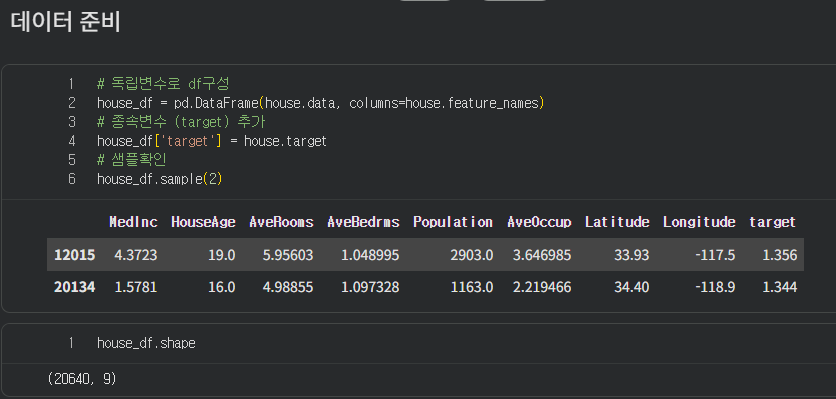
데이터 분석
- 8개의 독립변수와 1개의 종속변수간의 관계 정의 -> 다중회귀
- EDA를 통해서 분석
- 상관관계 분석 -> 피처 제거
- 독립변수대 종속변수간 분포, 비율 체크
- 정답이 밀집되어 있다면 (특정구간에)
- 스케일링 진행 -> 로그변환, 박스콕스 변환, . . .
상관관계 분석

이 시각화의 키 포인트는 10번코드의 나머지를 통해서 시각화를 각 차트에 넣어주는 부분이다.
실제로 개발을 할 떄 이런 식으로 많이 쓴다고 한다.
# 해석
- 우상향 : 양의 상관관계
- 우하향 : 음의 상관관계
# 피처별
- 'MedInc' : + 양의 상관관계
- 'HouseAge' : 파악불가 색을 다르게 하는등 조치 필요함
- 'AveRooms' : + 양의 상관관계
- 'AveBedrms' : - 음의 상관관계
- 'Population': - 음의 상관관계 약한
- 'AveOccup' : - 음의 상관관계 약한 / 신뢰구간이 너무 넓다. 상관관계가 없다고 봐야 할듯함.
- 'Latitude' : - 음의 상관관계 약한
- 'Longitude' : - 음의 상관관계 약한- 결론
- 피처(독립변수) 대 레이블(종속변수)간 상관관계가 모두 상이했음 -> 학습에 도움이 됨
- 모두 학습에 사용
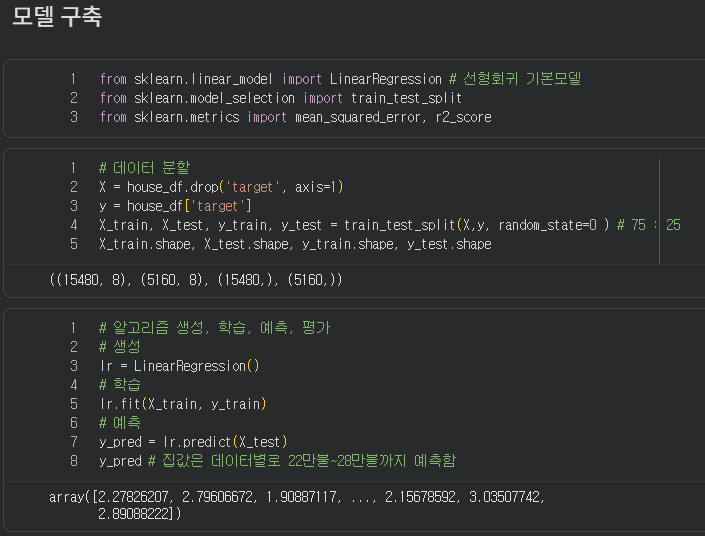



교차검증을 통해서 정확도를 올리기 위해서 최적화를 진행하였다.
아주 조금 개선되었다.
주요 알고리즘 확인
- 단순 선형회귀
- 베이스 라인 용도, 기본 모델
- 회귀 전용 ( 성능이 그렇게 좋진 않음)
- 라쏘
- L1 규제를 적용한 모델
- 특정 가중치의 값을 0으로 적용 -> 특정 피처(독립변수)는 학습에 사용 X - 피처 제거(다른 피처는 선택하는 의미)
- W(회귀계수중 가중치)의 절대값에 패널티 부여
- L1 규제를 적용한 모델
- 릿지
- L2 규제를 적용한 모델, 성능은 그닥 X
- 특정 가중치의 값을 작게 구성
- 특정 피처(독립변수)가 학습 시 영향력이 감소됨
- 모델 복잡성 감소시키는 효과
- 0으로 구성하지는 않음
- W의 제곱에 패널티 부여
- 엘라스틱 넷
- L1, L2 규제 모두 적용, 성능은 그닥 X
- 필요하면 제거 혹은 영향력 감소시키자
- L1, L2 규제 모두 적용, 성능은 그닥 X
- 라쏘
- 앙상블
- 분류에서 사용된 모델들은 거의 대부분 회귀도 동일하게 지원함
- 성능이 잘 나옴
- 보팅, 배깅, 부스팅, 스태킹 등등
- 로지스틱 회귀
- 분류용에서 주로 사용됨, 회귀도 사용 가능함
통계 모델링 vs 머신러닝 모델링

통계 관련
- 대명제 : 역사는 반복된다
- 예측 분석학
- 과거 데이터를 정합화 하여 테스트 -> 해당 결과에 대해 척도가 검증되면(증명) -> 해당 모델을 통해서 미래 예측 수행
- 변수
- 독립변수
- 피처, 설명변수, 관측치, 입력변수
- 종속변수
- 레이블, 반응변수, 결과변수, 응답변수, 측정된 변수
- 독립변수
- 변수
- 결론
- 변수들로 수학식을 계산(증명)하여, 실제에 적용 후 이를 추정하는 학문
변수 개수에 따른 용어
- 일변량
- 변수 1개
- 이변량
- 변수 2개
- 다변량
- 변수 2개 초과
통계학
- 정의
- 수치 데이터(연속형)의 수집, 분석, 해석, 구성 등을 다루는 수학의 분야
- 분야
- 기술 통계학
- 수치 데이터 -> 평균, 표준편차 데이터 요약
- 범주 데이터 -> 빈도, 퍼센티지(비중/비율) 데이터 요약(설명)
- 추론 통계학
- 전체 데이터(모집합)을 수집하는것은 불가능
- 표본(부분자료, 모집합을 대변하는 집합) 수집하여, 전체 모집합에 대한 결론을 추론
- 가설검정, 수치분석, 상관관계
- 기술 통계학
statsmodels 패키지
- 통계, 회귀를 모두 가진 패키지
- 파이썬을 이용한 통계 분석
- 시계열 데이터 분석 (금융(주식,환율, ..),센서(IOT,스마트팩토리),로그)
- 머신러닝/통계 : ARIMA, ...
- 딥러닝 : RNN 계열/LSTM, GRU등 계열 모델
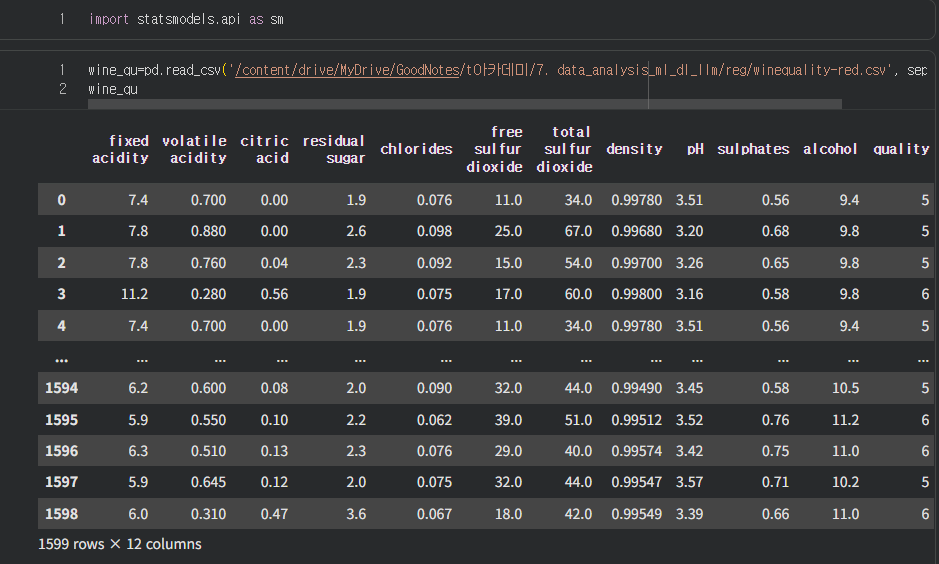
- quality : 와인 품질을 표현하는 정답
- 나머지 피쳐 : 와인 정보 (알콜도수, ph, ..)

정답으로 볼 수 있는 퀄리티의 고유값을 확인한다, 3~8등급으로 보인다
컬럼명을 전처리한다.
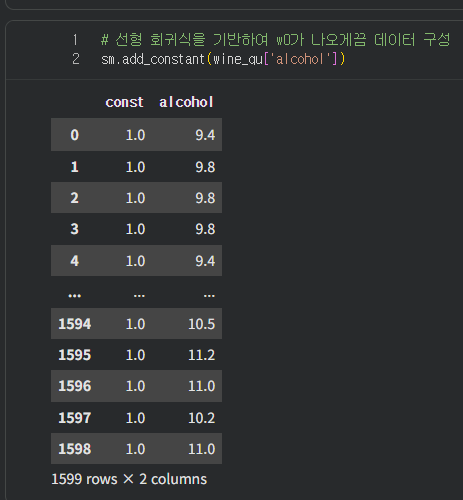
알콜이 와인 품질에 미치는 영향을 회귀분석으로 진행
- 통계 : 알콜, 품질 변수간의 관계를 수학적 표현
- 대립가설 : 알콜은 와인 품질에 영향을 미치지 않는다.(연구자(혹은 술 생산자) 자신이 세운 주장)
- 만약 이것을 직접적으로 입증하기가 어렵다면 귀무가설(반대 주장 기반)을 기각함으로써 이를 증명할 수 있음
- 귀무가설 : 알콜은 와인 품질에 영향을 미친다. <-> 대립 가설
- 대립가설 : 알콜은 와인 품질에 영향을 미치지 않는다.(연구자(혹은 술 생산자) 자신이 세운 주장)
- 머신러닝 : 알콜, 품질 변수간의 관계를 설명하시오, 모델링하시오.
- 참고
- 변수 2개 : 종속(품질) 1개, 독립(알콜) 1개
- 단순 선형 회귀
- y = w0 + w1x
- 변수 2개 : 종속(품질) 1개, 독립(알콜) 1개


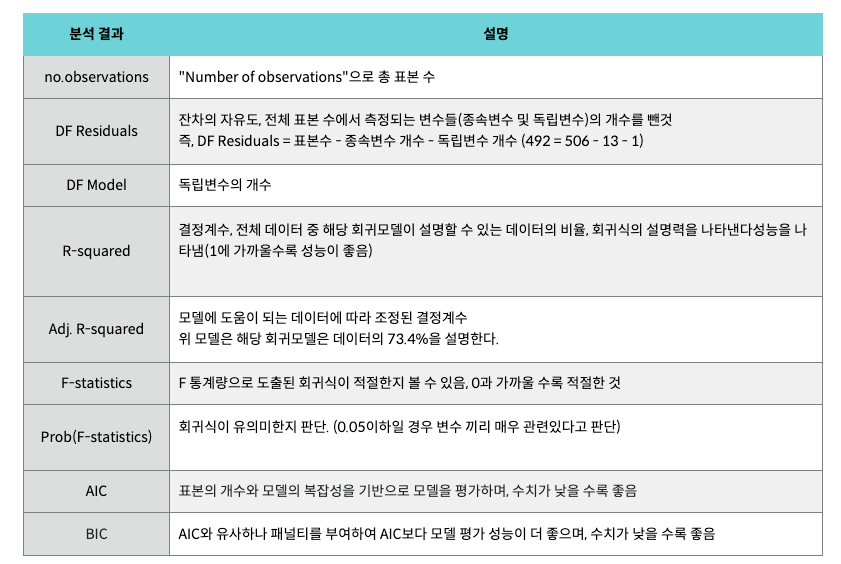
모델 실행한 결과의 해석이다.
결과값은 하단에
OLS Regression Results
==============================================================================
Dep. Variable: quality R-squared: 0.227
Model: OLS Adj. R-squared: 0.226
Method: Least Squares F-statistic: 468.3
Date: Tue, 09 Dec 2025 Prob (F-statistic): 2.83e-91
Time: 04:47:33 Log-Likelihood: -1721.1
No. Observations: 1599 AIC: 3446.
Df Residuals: 1597 BIC: 3457.
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 1.8750 0.175 10.732 0.000 1.532 2.218
alcohol 0.3608 0.017 21.639 0.000 0.328 0.394
==============================================================================
Omnibus: 38.501 Durbin-Watson: 1.748
Prob(Omnibus): 0.000 Jarque-Bera (JB): 71.758
Skew: -0.154 Prob(JB): 2.62e-16
Kurtosis: 3.991 Cond. No. 104.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
통계 모델 지표
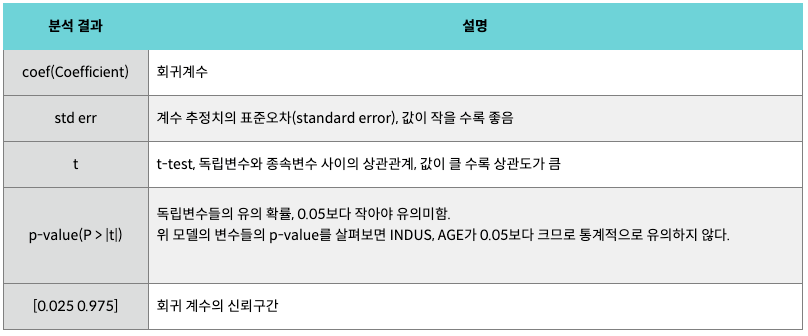


알코올 변수만 사용하지 않고 8개 독립변수 모두 사용해보았다.
OLS Regression Results
==============================================================================
Dep. Variable: quality R-squared: 0.361
Model: OLS Adj. R-squared: 0.356
Method: Least Squares F-statistic: 81.35
Date: Tue, 09 Dec 2025 Prob (F-statistic): 1.79e-145
Time: 05:20:26 Log-Likelihood: -1569.1
No. Observations: 1599 AIC: 3162.
Df Residuals: 1587 BIC: 3227.
Df Model: 11
Covariance Type: nonrobust
========================================================================================
coef std err t P>|t| [0.025 0.975]
----------------------------------------------------------------------------------------
const 21.9652 21.195 1.036 0.300 -19.607 63.538
fixed_acidity 0.0250 0.026 0.963 0.336 -0.026 0.076
volatile_acidity -1.0836 0.121 -8.948 0.000 -1.321 -0.846
citric_acid -0.1826 0.147 -1.240 0.215 -0.471 0.106
residual_sugar 0.0163 0.015 1.089 0.276 -0.013 0.046
chlorides -1.8742 0.419 -4.470 0.000 -2.697 -1.052
free_sulfur_dioxide 0.0044 0.002 2.009 0.045 0.000 0.009
total_sulfur_dioxide -0.0033 0.001 -4.480 0.000 -0.005 -0.002
density -17.8812 21.633 -0.827 0.409 -60.314 24.551
pH -0.4137 0.192 -2.159 0.031 -0.789 -0.038
sulphates 0.9163 0.114 8.014 0.000 0.692 1.141
alcohol 0.2762 0.026 10.429 0.000 0.224 0.328
==============================================================================
Omnibus: 27.376 Durbin-Watson: 1.757
Prob(Omnibus): 0.000 Jarque-Bera (JB): 40.965
Skew: -0.168 Prob(JB): 1.27e-09
Kurtosis: 3.708 Cond. No. 1.13e+05
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.13e+05. This might indicate that there are
strong multicollinearity or other numerical problems.
회귀 기본적 정리는 여기까지, 이제 캐글로 넘어갔다.
머신러닝 지도학습 회귀 _ 캐글데이터사용
개요
- 공공 자전거 대여 수요 예측 경진 대회
- 장소 : 워싱톤 DC
- 북반구, 바다와 가까움, 미국 수도
- 특성
- 날씨, 계절, 근무일, 휴무일, 날짜, 온도, 체감온도, 풍속
- 결측치 많이 존재함 (센서 고장, 불량)
- 평가지표
- RMSLE
- L => 로그 => 타겟 데이터의 정규분포 체크 필요 => 데이터는 밀집되어 있을 수 있다
- 타겟 데이터 전처리 필요!! - 로그 변환
- 박스콕스 변환
- 여존슨 변환
- 타겟 데이터 전처리 필요!! - 로그 변환
- L => 로그 => 타겟 데이터의 정규분포 체크 필요 => 데이터는 밀집되어 있을 수 있다
- RMSLE
- 배경
- 2014.5 ~ 2015.5 : 1년(대회 기간)
- 2011.1 ~ 12 : 1년 데이터
- 훈련데이터 : 1일 ~ 19일
- 테스트데이터(맞춰야할 데이터) : 20일 ~ 말일
- 일별 데이터(단위) 사용 고민
- 대여 방식
- 현 장소 픽업 -> 이동 -> 다른 장소에 반납


train데이터는 1일~19일까지이다, 그것을 먼저 확인해준다.

필요없는 컬럼 먼저 제거해준다.

전체 컬럼의 설명, 컬럼별 타입 또한 확인해준다.
EDA (데이터 전처리)
- 데이터별 경향(성향), 특이점 체크
- 파생변수 필요시 생성
- 피처 엔지니어링 전략 수립
타겟 데이터
- 정답 데이터
- 분류
- 범주형(명목형,순서형), 이산형
- 층화, 비율에 대해서 고민이 필요
- 회귀
- 연속형
- 분포
- 필요시 변화 처리 수행
- 분류

- 해석
- x축 : 특정 범위로 count값을 그룹화해서 표현
- y축 : 해당 그룹에 숙한 데이터가 몇개인가?(빈도)
- 왼쪽으로 편향되어있음
- 0~20정도 이하로 사용량이 체크된 데이터가 1900건 가량 발견되었다. +
- 데이터는 24시간 기준 1시간 단위로 측정됨
- 심야, 새벽도 데이터에 포함 -> 사용량 저조
- 실제로 적게 사용된 시간대도 포함
- 해당 분포를 가진 정답 데이터로 학습을 하면 좋은 결과 획득 어려움 -> 정규 분포를 가급적 따르면 좋은 결과를 낼 수 있음
- 정규 분포에 가깝게 데이터 분포 조정
- 로그 변환, 박스콕스 변환, 여존슨 변환
- 정규 분포에 가깝게 데이터 분포 조정



박스콕스변환, 안정적 분산을 기대할 수 있다, 원래는 상수를 추가하기도 하지만 이번 컬럼 count는 음수일 수 없기 떄문에 상수를 더하지 않아준다.

여존슨 변환, 이렇게 세 가지 회귀형 데이터 변환을 수행했다.

이상치 제거 위해서 데이터 확인한다, std가 1 이상이면 보통 한번 봐줘야된다.

weather 고유값 확인 후 천둥칠때는 한번만 타서 이상치로 제거해준다.
이후 파생변수 추가, 데이터 결합,분리 , 모델 구축 후 정확도 측정 등의 과정이 아직 남아있다.
오늘의 수업은 여기까지
'ASAC-SK플래닛 T아카데미 데이터 엔지니어' 카테고리의 다른 글
| 25.12.11 46일차 [머신러닝_비지도학습_군집화_차원축소] (0) | 2025.12.11 |
|---|---|
| 25.12.11 SK플래닛 T아카데미 | AI활용 데이터 엔지니어 과정 2기 모집 (0) | 2025.12.11 |
| 25.12.08 43일차 [머신러닝 분류 최적화, 베이지안 최적화 | 머신러닝 주요 알고리즘, 결정트리,앙상블, 스태킹] (1) | 2025.12.08 |
| 25.12.05 42일차 [ 머신러닝 지도학습 분류 캐글 playground 경쟁분야 | 머신러닝 분류 성능평가 | 머신러닝 분류 학습 | 머신러닝 분류 최적화] (0) | 2025.12.05 |
| 25.12.04 41일차 [ 머신러닝 지도학습 분류 캐글 playground 경쟁분야] (0) | 2025.12.04 |