오늘은 머신러닝 최적화 파트에서 베이지안 최적화 파트를 마무리한 후
머신러닝 필수 알고리즘들의 개요와 종류, 알고리즘 방식 등의 수업을 진행하였다.
베이지안 최적화


베이지안 최적화는 다양한 변수들을 설정한 후 함수 값을 모두 계산하지 않아도 최적의 변수를 찾는 최적화 도구이다.
설정상으로 100번의 결정트리를 사용하여 최적의 변수값을 찾아주고 모델의 정확도를 높여준다.

머신러닝 분류 _ 주요 알고리즘
결정트리- 기본모델중
개요
- 데이터에 존재하는 규칙을 학습을 통해서 자동으로 찾아내고, 이 규칙을 트리기반으로 만들어서, 분류하는 알고리즘
- 용어
- 노드
- 루트노드
- 트리의 시작점
- 일종의 규칙노드임
- 규칙노드
- 가지치기(분기작업이 진행, 브랜치, 서브트리 구성)를 하는 노드
- 규칙(피처를 이용하여 구성)이 존재함
- 반드시 서브트리가 존재함
- 리프노드
- 트리의 말단
- 더이상 분기 X
- 결정된 레이블(클레스, 정답)을 가짐
- 루트노드
- 노드
- 성능에 영향을 미치는 요소)
- 좌우 균형 -> 알고리즘별로 상이함
- 대칭(균형) -> 일반적으로 추가하는 형태
- 비대칭(불균형) -> 특수적, LightGBM
- 하이퍼파라미터
- 깊이(depth)
- 깊어지면 => 결국 다 맞춤(분류) => 과적합
- 연산비용 비쌈(시간 많이 소요)
- 최적화 => 적절한 깊이
- 깊어지면 => 결국 다 맞춤(분류) => 과적합
- ...
- 깊이(depth)
- 좌우 균형 -> 알고리즘별로 상이함
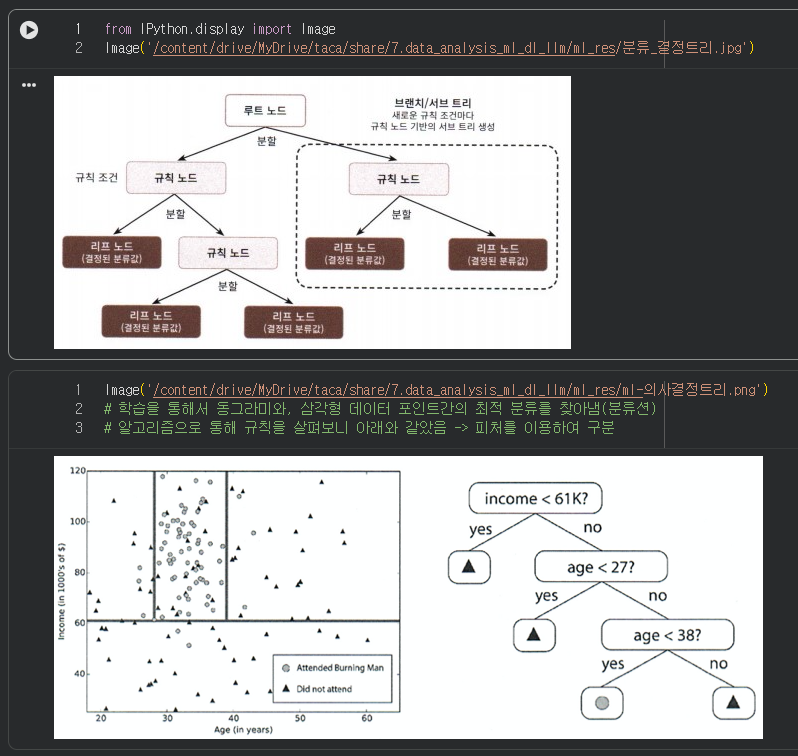
알고리즘 결정트리의 기본 도식화
규칙에 의거하여 맞는지 아닌지로 모델이 데이터의 분류를 예측하는 과정이다.
규칙
- 목표
- 데이터의 균일도(정보의 균일성, 가급적 같은 정답간 모임)를 높이도록(불순도가 최소화하게), 데이터 세트가 구성(분류)되게 규칙을 만드는 것
- 지표 -> 규칙 생성
- 엔트로피를 이용한 정보이득 지수
- 정보이득 지수 = 1 - 엔트로피(혼잡도, 불순도)
- 정보이득 지수를 최대가 되도록 방향성 잡음
- 엔트로피를 최소가 되게(낮게) 방향성을 잡음
- 지니 계수 (기본값)
- 값이 크면 불순도가 높다
- 방향성은 값이 낮게 구성되는 것을 목표
- 값이 크면 불순도가 높다
- 엔트로피를 이용한 정보이득 지수

결정트리 설명, 엔트로피가 혼란같은 뜻을 가진다. 데이터의 엔트로피가 낮고, 불순도가 낮고, 정보이득지수가 높아질때까지 조건을 찾아서 분할한다.
베이스라인
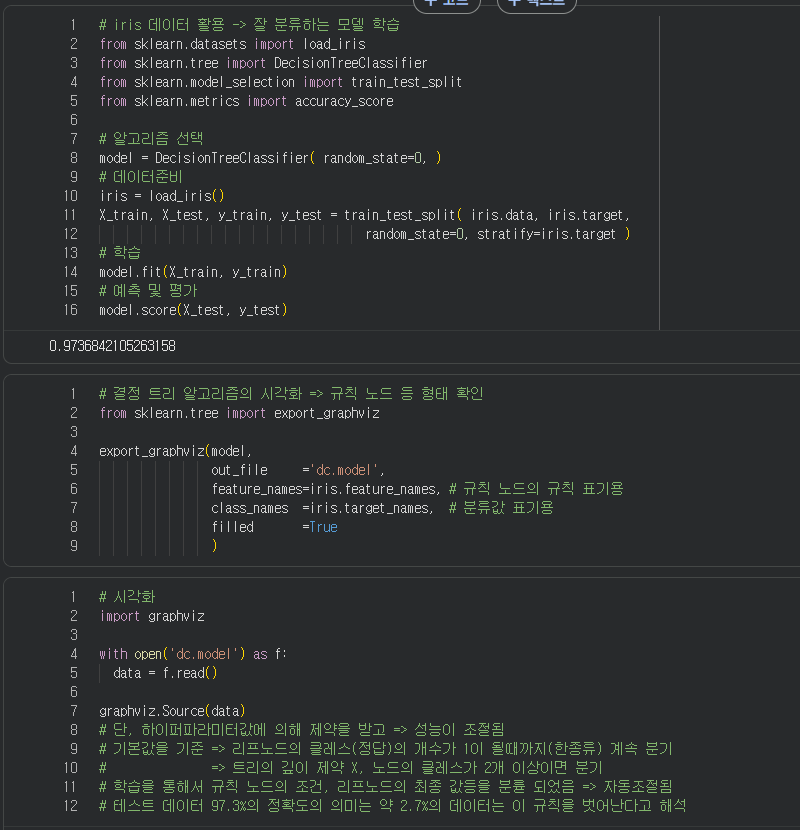

decisiontree 분류 알고리즘을 시각화하는 코드와 시각화 내용이다.
마지막 리프노드에 분류가 한 가지 종만 남을때까지 규칙 노드로 데이터를 분할하며 최종 값을 찾아내는 과정을 볼 수 있다.
피처 중요도를 기반으로 피처 제거
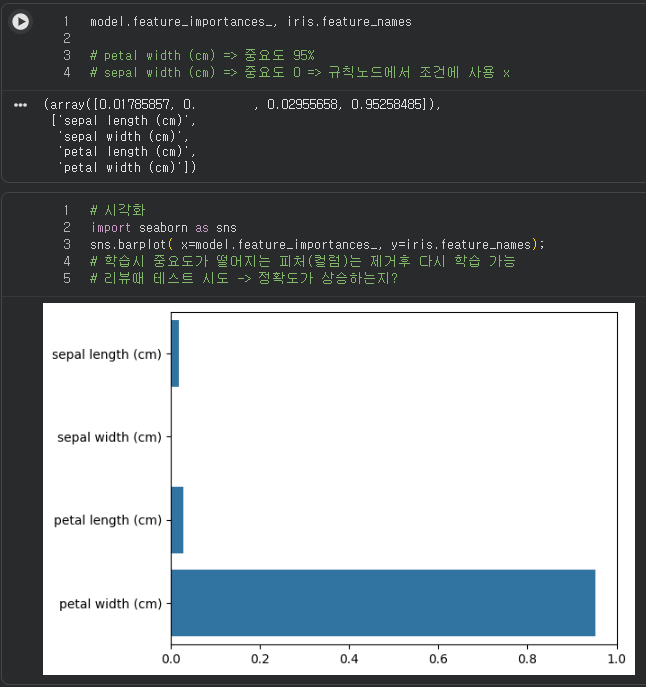
데이터를 평가하는 피처의 중요도를 시각화 한 자료와 수치이다.
현재 sepal 피처들은 중요도가 거의 없는것을 확인할 수 있다.
이러한 중요도가 떨어지는 컬럼은 제거 후 다시 학습할 시에 정확도가 상승할 수 도 있다.
학습된 모델 + 데이터 포인트 분류 시각화
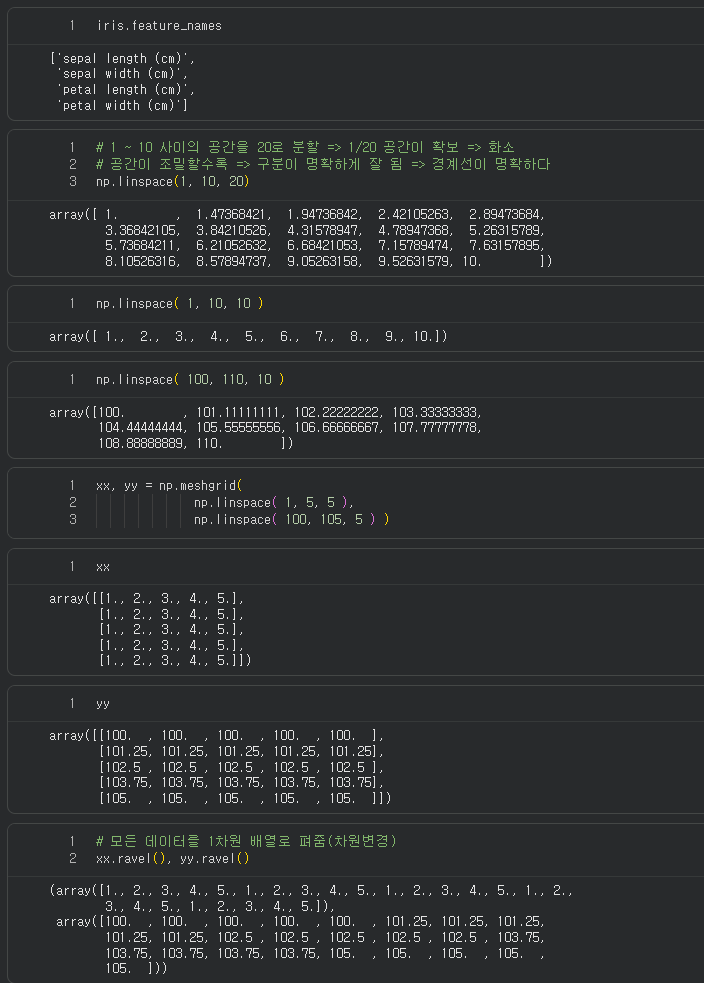



이 부분이 수업중에 내가 갑자기 정신도 못 차릴정도로 졸아버려서 수업 내용을 자세히 듣지 못했다...
그런데 제일 중요하고 제일 설명을 안 들으면 이해를 못할 부분이었다....ㅜㅜ
그래서 챗gpt의 힘을 빌려서 이 파트에 대한 설명을 들었다.
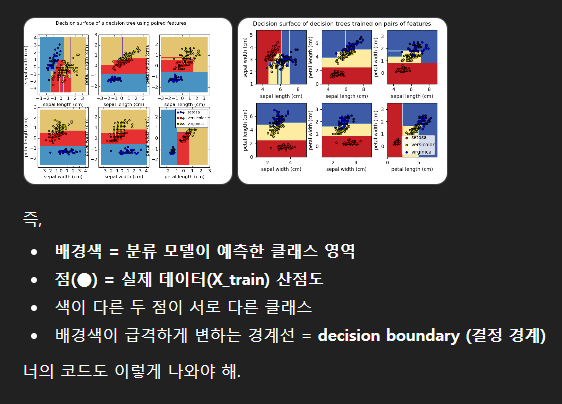
✅ 2. 코드와 수업 내용, 항목별 상세 설명
아래는 네 코드 구조를 명확히 해석한 거야.
📌 ① 산점도(scatter plot)
ax.scatter( X[:, 2], X[:, 3], c=y, s=40, edgecolor='k' )
X의 2번, 3번 컬럼만 사용 → 보통 petal length, petal width
y에 따라 점의 색이 달라짐 (클래스별 색상)
데이터 포인트가 어디에 모여 있는지 표시
📌 ② 축의 최소·최대값 가져오기 → meshgrid 생성
xlim_s, xlim_e = ax.get_xlim()
ylim_s, ylim_e = ax.get_ylim()
xx, yy = np.meshgrid(
np.linspace(xlim_s, xlim_e, seg_num),
np.linspace(ylim_s, ylim_e, seg_num)
)
산점도가 차지하는 범위를 기반으로
그 구역 전체를 가로·세로 seg_num(=200) 등분
즉, 각 칸은 하나의 화소(pixel)
모든 좌표쌍(xx, yy)을 만들고, 이후 모델에게 예측시켜 “영역”을 색칠함
📌 ③ 모델 학습
clf.fit( X[:, 2:], y )
X의 2번부터 끝까지 feature를 사용해 모델을 학습
(하지만 여기가 오류 원인… 원래는 X[:, [2,3]] 이어야 안전함.)
📌 ④ meshgrid 전체에 대해 예측
y_pred = clf.predict( xy )
xy는 meshgrid 화소 좌표 → shape = (seg_num², 2)
각 좌표마다 모델이 어떤 클래스로 분류할지 예측함
→ 이게 배경색이 됨
📌 ⑤ contourf로 배경 영역(=결정영역) 색칠
ax.contourf(xx, yy, y_pred.reshape(xx.shape), cmap='rainbow', alpha=1.0)
contourf = 등고선 + 면적 채우기
z축 역할 = “예측한 클래스 번호” (0/1/2 등 숫자가 z값처럼 취급)
즉, x축, y축의 좌표마다 z값=클래스가 색깔로 보이게 됨
✅ 3. 개념적 설명 — 왜 이런 시각화를 하는가?
이 시각화는 머신러닝 수업에서 매우 중요한 의미가 있어.
📌 ① Decision Boundary(결정 경계)
모델이 class A와 class B를 구분하는 경계선(또는 경계면)을 학습하게 되는데,
이 경계의 형태를 관찰할 수 있음.
선형 모델(SVM(linear)) → 직선 경계
비선형 SVM → 곡선 경계
DecisionTree → 계단형 경계 (block 형태)
📌 ② z축의 의미는 무엇인가?
3차원 z축이 실제 그래프에 보이지 않아도, 내부적으로는 이렇게 동작함:
x좌표 y좌표 z = 예측 클래스
1.2 0.4 0
1.3 0.5 0
2.1 1.4 1
… … …
이 z 값을 색상으로 표현한 것이 contourf임.
즉, z축 = "분류모델의 예측 결과" 를 의미하는 개념적 축이다.
📌 ③ 머신러닝 모델의 성향 파악 가능
예:
SVM → 자연스럽게 곡선 형태의 Soft Margin
DecisionTree → 계단형, 박스형 경계 → 과적합 패턴이 흔함
KNN → 노이즈 영향을 많이 받음 → 들쭉날쭉한 경계
🎯 최종 정리
✔ 정상작동 시 나오는 시각화
→ 산점도 + 배경 색칠된 분류 영역 + (암묵적 z축 = 예측 클래스)
✔ 코드가 하는 일
산점도 → 데이터 위치 확인
meshgrid → 전체 공간을 잘게 나눔
모델에게 각 공간의 좌표를 넣어 “무슨 클래스인지” 예측
contourf → 예측한 클래스를 색으로 채워서 결정영역 표시
✔ 개념
2D feature space에서 "모델이 어떻게 구분하는지"를 시각적으로 확인
z축은 "예측 클래스"라는 개념적 값
색깔 변화가 곧 decision boundary즉
점 = 데이터
색 = 종
으로 모델이 판단했다는 사실을 시각화한 내용인것이다.
앙상블
- 여러개의 알고리즘 생성(동일, 서로다른)하여, 학습(일반, 교차검증, 메타) 진행 후, 각각의 모델이 예측한 값을 처리(다수결, 합산 평균)하여 최종 결과 도출
- 약한 모델(분류기)를 모아서 강한 모델(분류기) 생성하는 기법
- 집단 지성, 단일 모델보다는 상대적으로 정확도가 높다
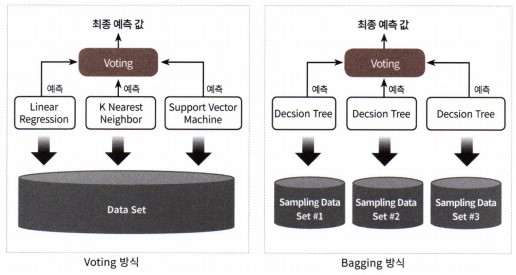
보팅
- Voting
- 서로 다른 알고리즘 n개 사용
- 비중은 일반적 1: 1: .... (동등)
- 경우에 따라서는 비대칭 비율로 가능함
- 의사결정 종류
- 하드 보팅:다수결
- 소프트 보팅:합산평균
- 동일데이터로학습


보팅을 구성하고 돌린 값이다. 기본 베이스모델보다는 높은 성능을 보팅을 통해서 만들어냈고
다양한 알고리즘들을 통해서 단순한 처리가 아닌 여러 알고리즘이 돌아가도록 세팅 후 돌린 결과이다.
배깅
- Bagging
- 동일 알고리즘 n개
- 의사결정(소프트보팅)
- 데이터는분할(중복허용)
- 부트 스트래핑 기법
- 대표알고리즘
- 랜덤포레스트
- DT가 n개 구성되어 배깅 진행
- 신규로 만들고 싶다면
- BaggingClassification을 통해서 구현
- 랜덤포레스트


이는 한 가지 알고리즘을 사용하고 데이터를 나누어서 각자 다른 데이터로 착각하도록 설계하는 알고리즘이다.
다양성을 확보하고, 정확도를 올려주는 역할을 한다. 결과는 일단은 보팅이랑 같다.
(*)부스팅
- Bosting
- 높은 성능 발휘하는 모델
- 원리
- 약한 분류기로 순차적 학습 및 예측 수행
- 잘못 예측한 케이스 발생
- 해당 데이터에 대해 가중치(weight) 부여 -> 오류 개선
- 해당 유형은 딥러닝의 학습 및 최적화와 유사함
- 가중치 부여는 => 미세조정을 통해서 값의 크기도 컨트롤함
- 원하는 성과가 나올때까지 반복
- 학습 => 평가 => 가중치부여 => 학습 => 평가 => 가중치 부여 => ..... => 목표치에 수렴
- 학습 시간 오래 걸림
AdaBoost (부스팅 계열 초기모델)

GBM
- Gradient Boost Machine
- 경사하강법(딥러닝에서 최적화에 주로 사용) 기법 도입
- 초기 AI에서 최적 분류선을 찾기 위해 나온 기법
- 경사하강법을 이용하여 가중치를 업데이트(가중치 조정에 관려함)
- 오차값을 최소화
- 미세조정을 통해서 진행(학습률, eta, learning_rate => 0.0001 세팅)
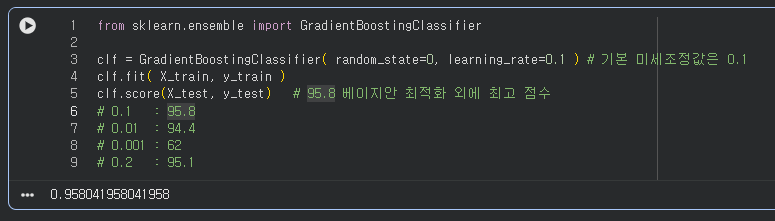
XGBoost
- GBM 개선
- 느린 학습 속도
- 과적합 방지 기능
- API
- 파이썬 래핑
- 사이킷런 래핑

GBM의 단점인 느린 학습속도를 개선하여 나온 알고리즘으로 분기 기준 시각화 또한 가능하다.
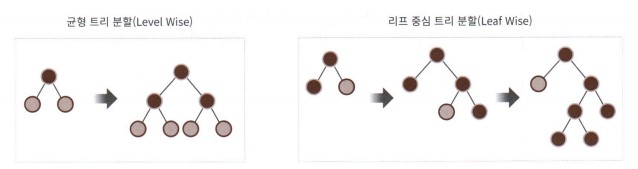
LightGBM
- MS 개발
- XGBoost 개선
- 학습 시간 개선
- 하이퍼파라미터 개선(XG의 하이퍼가 너무 많음)
- 특징
- 리프 노드 중심으로 가지치기 진행
- 비대칭 구조 트리로 생성됨(균형 x, 성과중심)
- 리프 노드 중심으로 가지치기 진행

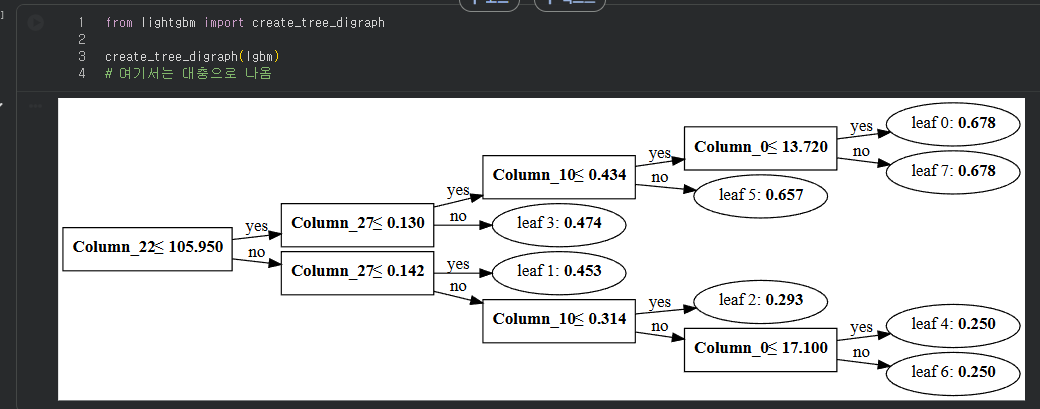
스태킹
- stacking
- 스택구조 연상
- 특징
- 1차 학습
- 기존 학습법 그대로 적용
- 2차 학습
- 1차 학습의 결과물 => 예측결과를 2차 학습의 데이터로 사용
- 메타 학습 기법
- 직접 구현!! (로직으로 구성)
- AutoML에는 통상 누락(혹은 제외되어 있음)
- 1차 학습

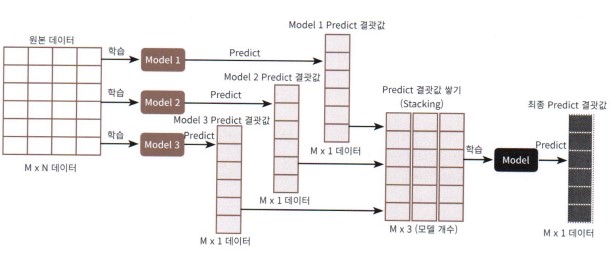




스태킹의 순서를 정리한 이미지이다. KFOLD의 CV 방식을 가져온 알고리즘 형태로 스태킹이 많이 됐지만
그래도 아직까지 대부분의 알고리즘에서 부스팅이 최고의 성능을 가지고 있다고 한다.
오늘의 수업은 여기까지
주석 달 시간이 없어 으아악
'ASAC-SK플래닛 T아카데미 데이터 엔지니어' 카테고리의 다른 글
| 25.12.11 SK플래닛 T아카데미 | AI활용 데이터 엔지니어 과정 2기 모집 (0) | 2025.12.11 |
|---|---|
| 25.12.09 44일차 [머신러닝_지도학습_회귀] (0) | 2025.12.10 |
| 25.12.05 42일차 [ 머신러닝 지도학습 분류 캐글 playground 경쟁분야 | 머신러닝 분류 성능평가 | 머신러닝 분류 학습 | 머신러닝 분류 최적화] (0) | 2025.12.05 |
| 25.12.04 41일차 [ 머신러닝 지도학습 분류 캐글 playground 경쟁분야] (0) | 2025.12.04 |
| 25.12.03 40일차 [ 머신러닝 전체 플로우 진행, 간단한 모델 구성 | 머신러닝 지도학습 분류 캐글 playground 경쟁분야] (1) | 2025.12.03 |